
Anthropic had the week’s biggest release, putting near-flagship agentic capability into Claude Sonnet 5 and shipping it everywhere on day one, then following with Claude Science, a research environment built around reproducibility. The company also closed out a two-week saga by redeploying Fable 5 and Mythos 5 once US export controls lifted, revealing the ban rested on a capability the model never uniquely had. The contrast with OpenAI was sharp, which previewed GPT-5.6 behind a government review process it openly dislikes. Underneath the policy fights, agents kept getting more capable and more independent, with Codex taking over every department at OpenAI, Cursor putting coding agents on the iPhone, and OKX building a marketplace where agents pay each other directly. Closer to home, Toronto’s Vector Institute released an open-source tool for catching biased language in writing and training data. Here’s what mattered.
Listen to the AI-Powered Audio Recap
This AI-generated podcast is based on our editor team’s AI This Week posts. We use advanced tools like Google NotebookLM, Descript, and Elevenlabs to turn written insights into an engaging audio experience. While the process is AI-assisted, our team ensures each episode meets our quality standards. We’d love your feedback—let us know how we can make it even better.
TL;DR
- Anthropic launched Claude Sonnet 5, its most agentic mid-tier model, pulling performance close to Opus 4.8 at lower cost.
- Anthropic also released Claude Science in public beta, a macOS and Linux research app that runs analyses, queries 60+ scientific databases, and welds the code, environment, and conversation to every figure for full reproducibility. It is an app, not a new model.
- OpenAI opened a limited preview of GPT-5.6 (Sol, Terra, Luna) behind a government access gate, sharing partner names with US officials before any wider release. The company says it does not want this review process to become the norm.
- Cursor launched a native iOS app in public beta, letting developers start, steer, and merge agent work from their phones, with cloud agents that run asynchronously toward merge-ready PRs.
- OKX launched a marketplace where AI agents hire one another, settle payments with stablecoins, and build on-chain reputations, betting agentic commerce becomes a trillion-dollar market within five years.
- Codex became the primary AI tool for every department at OpenAI, including Legal, Finance, and Recruiting, accounting for 99.8 percent of internal output tokens by June 2026. Non-developer adoption outpaced developers across every group.
- Anthropic redeployed Fable 5 and Mythos 5 after US export controls lift, revealing the ban rested on a bypass that competing models could reproduce too. It proposes an industry framework for scoring jailbreak severity and formalizes pre-release government access.
- Toronto’s Vector Institute released UnBias-Plus, a free, open-source tool that detects and rewrites biased language in writing and AI datasets, aligned with Canada’s national AI strategy.
🤖 Model Releases
Anthropic Releases Claude Sonnet 5, Its Most Agentic Mid-Tier Model
Anthropic has launched Claude Sonnet 5, positioning it as the most agentic Sonnet model to date and pulling mid-tier performance close to where its flagship sat only months ago. The pitch is that Sonnet 5 narrows the gap to Opus 4.8 on the things that define agentic work, including reasoning, tool use, coding, and knowledge work, while costing meaningfully less. Anthropic notes that the agentic era arrived for many developers with earlier Sonnet models, and that recent capability gains had concentrated in the pricier Opus line. Sonnet 5 is the attempt to bring that progress back down a tier.
The model can plan, operate browsers and terminals, and run on its own at a level Anthropic says previously required larger, more expensive models. On the agentic search benchmark BrowseComp and the computer-use benchmark OSWorld-Verified, Sonnet 5 improves cleanly over its predecessor Sonnet 4.6, with Opus 4.8 still ahead on raw accuracy. The framing is that Sonnet 5 and Opus 4.8 now cover one continuous cost-performance range, letting users dial effort levels to balance price against accuracy rather than jumping between tiers. Early access testers reported that it finishes complex tasks where older Sonnet models stopped short and checks its own output without being asked.
Pricing and availability are aggressive. Sonnet 5 is the default for Free and Pro plans from today and is available across Max, Team, Enterprise, Claude Code, and the Claude Platform. Introductory API pricing runs $2 per million input tokens and $10 output through August 31, after which it moves to $3 and $15. On safety, Anthropic reports Sonnet 5 shows lower rates of misaligned behaviour, hallucination, and sycophancy than Sonnet 4.6, and is better at refusing malicious requests and resisting prompt-injection hijacks, though it scores worse on these measures than Opus 4.8 and Mythos Preview. Notably, the model was not trained for cybersecurity work and cannot build a working exploit, scoring far below Opus 4.8 and Mythos 5 on offensive cyber tasks. It still ships with cyber safeguards enabled by default, matching those in Opus 4.7 and 4.8.
Why it matters: While the GPT-5.6 launch and the Mythos ban turned on models getting more dangerous at finding and exploiting vulnerabilities, Anthropic is shipping a capable agentic model that deliberately cannot do that, and treating the absence as a feature worth measuring. That points to a possible split in how frontier labs position their lineups: the dangerous-capability models routed through government gates and verification programs, and the broadly available workhorses kept deliberately weak on offensive cyber so they can ship to everyone without the same friction.
OpenAI Previews GPT-5.6 Behind a Government Access Gate
OpenAI has opened a limited preview of its GPT-5.6 series, organized into three tiers: Sol as the flagship, Terra as a mid-range option for everyday work, and Luna as the low-cost speed model. The company positions Terra as roughly matching GPT-5.5 performance at half the price, with Luna offering strong capability at the bottom of the cost range. Per-million-token pricing runs $5 input and $30 output for Sol, $2.50 input and $15 output for Terra, and $1 input and $6 output for Luna.
The naming convention is new. The number marks the generation and the names mark capability tiers that can each progress on their own schedule. The release also adds a max reasoning effort setting and an ultra mode that pulls in subagents for heavier work, and OpenAI says it will run Sol on Cerebras hardware at up to 750 tokens per second starting in July.
Most of the announcement centres on cybersecurity and the release process. OpenAI describes Sol as its strongest model yet for security tasks, including vulnerability research and exploitation, and reports state-of-the-art results on Terminal-Bench 2.1. The company says Sol does not cross the Cyber Critical threshold in its Preparedness Framework. In testing against Chromium and Firefox, the model surfaced bugs and the components of an exploit but did not build a working full-chain attack on its own under the conditions tested.
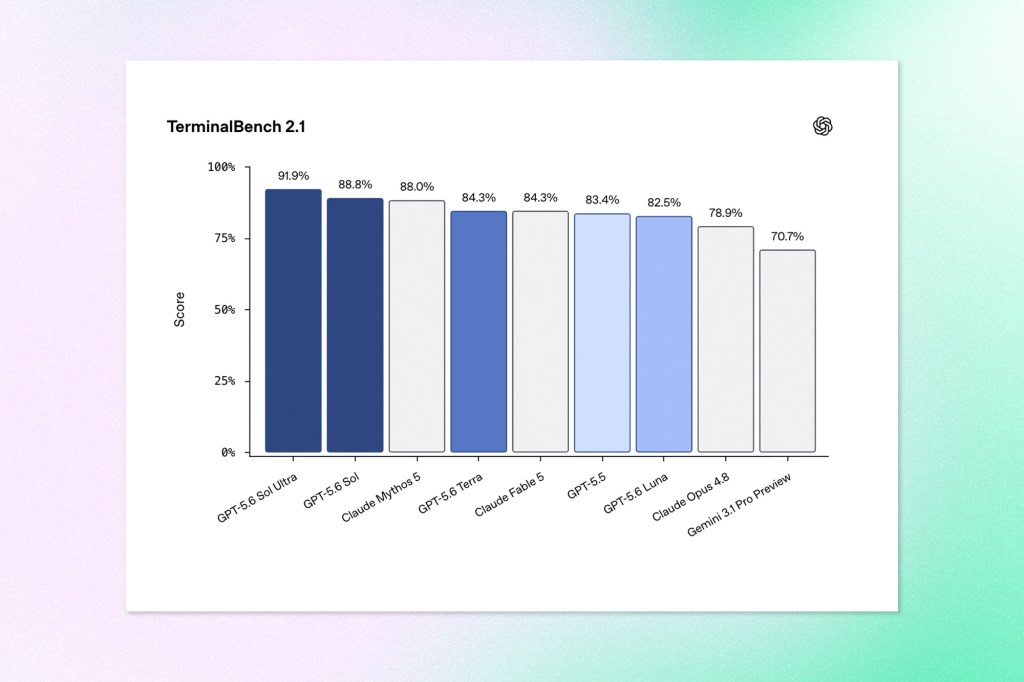
The rollout itself is unusual. OpenAI says it previewed the models and their capabilities to the US government ahead of launch, and that at the government’s request it is starting with a small group of vetted partners whose names were shared with officials before any wider release. The company states plainly that it does not want this kind of government review to become the standard path for future launches, framing the current step as a short-term move while it works with the Administration on a cyber Executive Order framework. The model ships with a layered safeguard system, and OpenAI says it spent more than 700,000 A100-equivalent GPU hours on automated red-teaming to find jailbreaks that work across many contexts rather than single prompts.
Why it matters: A lab can argue a model stays below its own danger threshold while still treating it as risky enough to route through government review, and OpenAI is doing both at once. That tension tells you the benchmark thresholds are no longer where the decisions actually get made. For anyone outside the US, the precedent is the part to watch. A small group of partners cleared with the US government before broader release is a different distribution model than open API access on day one, and Canadian developers, enterprises, and cyber defenders sit on the far side of that gate by default. If a government preview becomes a soft requirement for frontier launches, access timing starts to depend on where you are as much as what you are willing to pay, and OpenAI’s own discomfort with the arrangement does not change who waits.
🛠️ Products and Platforms
Anthropic Launches Claude Science, a Research Environment for Working Scientists
Anthropic has released Claude Science in public beta, a desktop app aimed at researchers that runs analyses, queries scientific databases, and tracks every step from raw data to manuscript. The key clarification up front: this is not a new model. It uses the same Claude models a user’s plan already includes, and what is new is the layer around them, namely the scientific tools, database connections, and compute integrations that let Claude run full analyses on a researcher’s own infrastructure. It is available now for macOS and Linux.
Reproducibility is the central design idea. Every figure, table, and notebook ships with the exact code, environment, and conversation that produced it, so a result can be reproduced, edited, or defended months later. The app renders proteins, structures, and molecules natively, iterates on figures through plain-language instructions, and drafts manuscripts in the same place the analysis happens. It manages its own compute, building environments and scaling across a laptop, a Linux box, an HPC login node, or anywhere from one GPU to hundreds, with persistent Python and R kernels. It arrives pre-configured for major life-science domains including genomics, single-cell, proteomics, structural biology, and cheminformatics, can read literature, and can query more than 60 scientific databases. Connectors bring in internal APIs, electronic lab notebooks, and custom pipelines, and partners including LatchBio and Helix are wiring their data infrastructure in through MCP.
Early testimonials lean on time compression and accessibility. Researchers describe going from raw data to a publication-quality figure in a single session, and a non-computational biologist describes running analyses that would not otherwise have been feasible. One UCSF principal investigator reported the app surfaced a laboratory virus contaminant in bulk RNA-seq data that the lab had spent close to a year failing to find. Drug-discovery firms including Xaira frame it as shortening the path from hypothesis to validation across their pipelines.
Why it matters: The reproducibility framing is the part worth taking seriously, because it targets a problem that predates AI and that AI has arguably made worse. Welding code, environment, and the prompting conversation to every figure is a direct answer to the worry that AI-assisted analysis produces results nobody can retrace, and in a field where a finding has to survive peer review and replication, that auditability may matter more than raw speed.
Cursor Launches an iOS App for Running Agents from Anywhere
Cursor has launched a native iOS app in public beta, letting developers start and steer coding agents from their phones. The pitch is mobility: kick off an agent when an idea hits, get notified when work is ready, and merge pull requests without opening a laptop.
The app works in two modes. You can launch always-on agents that run in the cloud, or use Remote Control to direct agents already running on your computer, with a setting that keeps your machine awake to stay reachable. Starting an agent mirrors the desktop flow: pick a repo, choose any frontier model, describe the task by voice, and use slash commands to guide it. Live Activities on the lock screen and push notifications keep you posted when an agent finishes, needs input, or is ready for review.
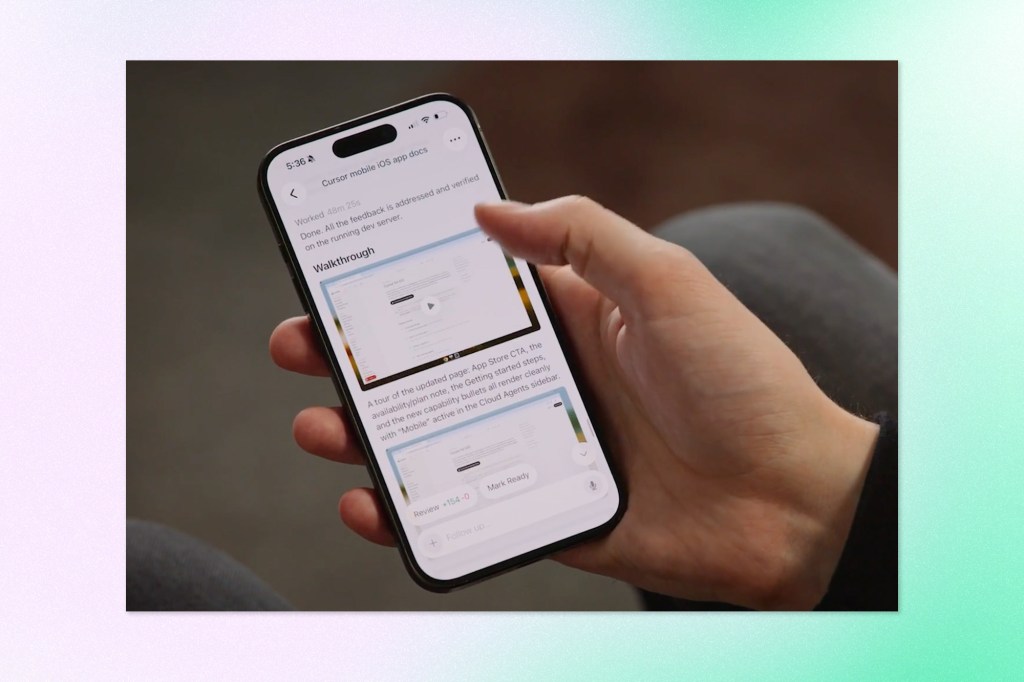
Cursor frames the use cases around being away from your desk: investigating an incident when you get paged at lunch, reproducing a customer bug from your phone, or screenshotting user feedback from X, annotating it, and sending it to an agent as visual context. Cloud agents run in isolated virtual machines with full development environments, so they can work asynchronously toward merge-ready PRs, and work can be handed off between local and cloud environments in both directions. The company says repo-less chats are coming next, and that teams already use the app with MCPs to query Datadog logs and summarize Slack activity. The beta is available on all paid plans, with 75% off Composer 2.5 runs through July 5.
Why it matters: The phone is not the interesting part; the asynchronous model is. Cursor is betting that coding is becoming something you supervise rather than something you sit and do, and a mobile app only makes sense if agents are competent enough to run unattended while you cook dinner. That is a real claim about where agent reliability has landed, and it reframes the developer’s job from writing code to reviewing artifacts an agent produces. For a development shop, the workflow shift is the thing to watch. If incident response and bug fixes can start from a lock screen, the bottleneck moves from how fast someone can get to a keyboard to how well work is scoped and how trustworthy the review step is. That cuts both ways. It compresses response time, but it also normalizes always-on availability in a way worth thinking through before “I can merge from my phone” quietly becomes “I am expected to.”
Ready to explore what AI can do for your organization?
Crypto Exchange OKX Launches a Marketplace Where AI Agents Pay Each Other
Crypto exchange OKX has launched OKX AI, a marketplace where AI agents can hire one another, settle payments on their own, and build portable on-chain reputations. It opened to developers on Tuesday after a closed beta with 50 early service providers, and it builds on earlier OKX work that let agents hold digital wallets, pay with stablecoins, and carry persistent identities. The company casts it as a step beyond crypto trading toward becoming a broader fintech firm, betting that a meaningful share of its next customers will be autonomous software rather than people.
The pitch rests on an “agent economy” thesis. CEO Star Xu argued the coming decade will be defined by one-person companies clearing more than a million dollars in revenue because each person effectively gains an unlimited workforce, and that the financial plumbing built for humans does not fit autonomous software. Chief marketing officer Haider Rafique put a number on it, suggesting agentic commerce could reach a trillion dollars within five years, driven by micropayments and around-the-clock settlement that conventional payment rails handle poorly. Blockchain-based stablecoin payments are the mechanism that makes low-value transactions between agents practical.
Early builders sketch what the marketplace is for. CertiK offers a service that lets an agent assess the security of a wallet or token before transacting, CoinAnk sells live market data on a pay-per-query basis, and GenLayer is bringing dispute-resolution infrastructure that its CEO describes as a digital court system for when agent contracts go wrong. Developers connect through Onchain OS, OKX’s toolkit, with no OKX account required, and the platform works with coding tools including Claude Code, Codex, Hermes, and OpenClaw. OKX says it is applying the same fraud detection and compliance systems that run its exchange, and is rolling out in phases. India features prominently in the plans, since developer products face fewer regulatory hurdles there than the spot trading OKX suspended in the country in 2024.
Why it matters: The interesting bet is not that agents will transact but that they will need to discover each other, price work, and settle disputes without a human in the loop, which is a different and harder problem than giving one agent a wallet. GenLayer’s CEO named the real constraint when he said the challenge is distribution, not technology, and that OKX already has it. That is the part worth weighing skeptically, because an agent marketplace is only as valuable as the trust layer underneath it, and “portable on-chain reputation” plus a “digital court system” are promises that have to survive contact with adversarial actors before they mean anything. For anyone building with agents, the development to track is the standardization attempt rather than the crypto framing. If agent-to-agent payment and identity rails do consolidate, the question of who owns that layer becomes significant fast, and a crypto exchange with 150 million users and NYSE-parent backing is positioning to be that owner.
📈 Agentic AI
Codex Becomes the Default Tool for Every Department at OpenAI
A new OpenAI economic research paper tracks how its coding agent Codex spread across the company over the past year, and the headline is that the tool stopped being just for engineers. By June 2026, Codex accounted for 99.8 percent of weekly output tokens generated inside OpenAI, and every department had adopted it as the primary AI tool for work, including non-technical functions like Legal, Finance, and Recruiting. Through August 2025, the average OpenAI worker spent less than 10 percent of their tokens on Codex. The paper frames this as a shift in the basic unit of knowledge work, from short self-contained chatbot exchanges to delegated tasks an agent runs on its own for minutes or hours.
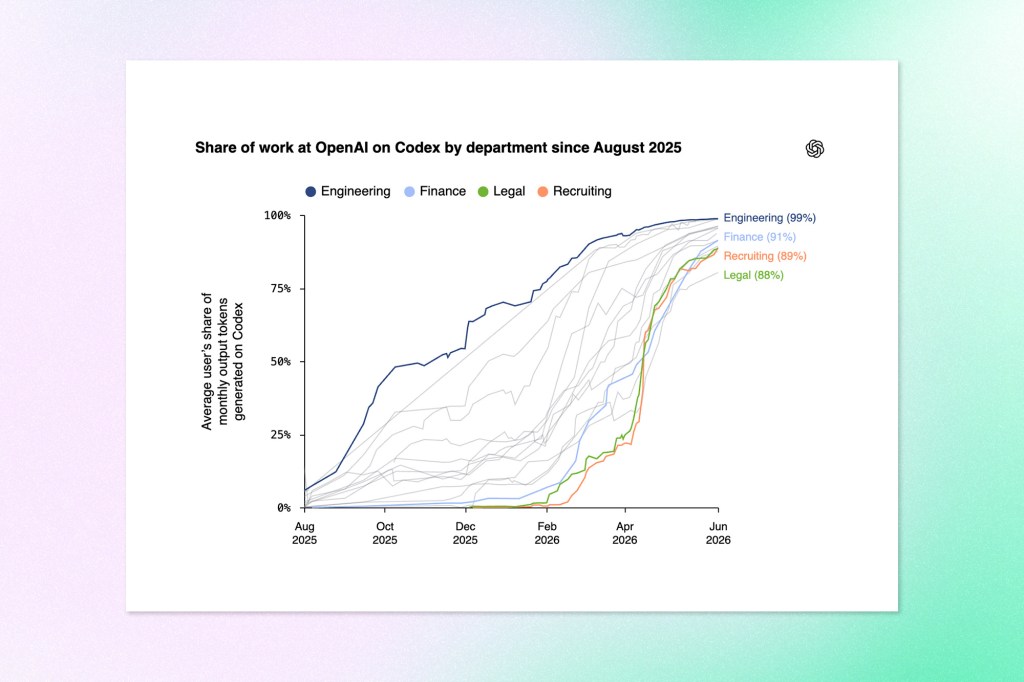
The growth concentrated in two places. First, in task length: by May 2026, 80.6 percent of sampled individual users had made at least one Codex request estimated to exceed 30 minutes of human work, 70.2 percent crossed the one-hour mark, and 25.6 percent made a request estimated to exceed eight hours. Among the heaviest internal users, the 99th percentile regularly generated more than 60 hours of agent work in a single day by running multiple agents in parallel. Second, in who was using it: non-developer adoption outpaced developer adoption across every group, rising 137-fold among individual users and 189-fold among organizational users since August 2025. Engineering moved first and now generates 99 percent of its tokens on Codex, while Legal, Finance, and Recruiting crossed into majority use around April 2026 but transitioned faster once they started.
The paper also documents work crossing job boundaries. More than a quarter of the Codex work done by people in business functions was engineering or coding, suggesting agents lower the cost of stepping into adjacent tasks that previously needed specialized support. OpenAI is careful to note this does not mean every non-developer uses Codex the way an engineer does, only that more of them are using it for some kind of agentic work. The company positions its own internal adoption as a preview of what broad, low-friction access to capable agents produces over time.
Why it matters: The obvious caveat is that this is OpenAI measuring OpenAI, the most agent-saturated workplace on earth, so the 99.8 percent figure says more about a ceiling than a near-term norm. The more useful signal sits underneath the numbers: the fastest growth came from non-developers and from work that crossed job descriptions. If that pattern holds outside OpenAI, the competitive pressure on knowledge workers shifts from learning a specific tool to being willing to delegate work they would once have routed to a specialist.
🔒 Cybersecurity
Anthropic Redeploys Fable 5 and Mythos 5 as US Export Controls Lift
The export saga that shaped much of this week’s news has resolved. Anthropic restored access to Fable 5 and Mythos 5 after the US government lifted the controls it imposed on June 12. Fable 5 returned globally on July 1 across the Claude Platform, Claude.ai, Claude Code, and Cowork, with cloud availability to follow. Mythos 5 access was restored to a set of US organizations after government approval on June 26. For Pro, Max, Team, and select Enterprise plans, Fable 5 is included for up to half of weekly usage limits through July 7, then moves to usage credits.
The explanation undercuts the original severity. The controls followed an Amazon report showing a way to bypass Fable 5’s safeguards and get it to identify vulnerabilities, including one case producing exploit code. Anthropic’s review found the technique exposed nothing unique: less capable models including Opus 4.8, GPT-5.5, and Kimi K2.7 could identify the same vulnerabilities, and every model tested, down to Haiku 4.5 and Sonnet 4.6, could reproduce the same demonstration. The company calls it a borderline case involving routine defensive work, and trained a new classifier that now blocks the technique in over 99 percent of cases, routing flagged requests to Opus 4.8. Commerce Department researchers judged the safeguards extremely strong.
The forward-looking piece is a proposed industry standard. Anthropic is working with Amazon, Microsoft, Google, and other Glasswing partners on a shared framework for scoring jailbreak severity across four axes: capability gain, breadth, ease of weaponization, and discoverability. It is also formalizing pre-release government access and evaluation for frontier models, rapid safeguard sharing, and joint research, and launching a HackerOne program for Fable 5 jailbreak submissions.
Why it matters: The striking admission is that the ban rested on a capability the model did not uniquely have. If Haiku 4.5 and a half-dozen competitors could produce the same exploit demonstration, then two weeks of global suspension came down to a safeguard false positive rather than a real Mythos-level threat, which is a costly lesson in how blunt the current tools for judging model risk are. That is why the jailbreak-severity framework will outlast the incident: nobody had an agreed standard for how serious the Amazon finding was, so the response defaulted to maximum caution.
🍁 Canadian AI
Vector Institute Releases an Open-Source Tool for Detecting Biased Language
Toronto’s Vector Institute has launched UnBias-Plus, a free open-source tool that scans for biased language in both written content and AI training data. The tool checks for bias across race, gender, age, and political framing, explains why each instance was flagged, and proposes neutral alternatives. Vector research scientists position it as useful both for everyday writing and for cleaning the datasets that models learn from.

The problem it targets is well documented. Because large language models train on human-generated text, they tend to reproduce the social biases in that text. Vector points to examples already on the record: algorithmic hiring tools in the US that recreated systemic bias against Black and Asian applicants, and a London School of Economics study finding that AI tools used by UK councils downplayed the severity of women’s health issues relative to men’s. Applied machine learning scientist Shaina Raza framed the motivation around who bears the cost, noting that the people most affected by biased language, such as a patient whose clinical notes carry hidden assumptions or a job candidate who never learns why a door keeps closing, are usually the last to know it is there.
Vector Institute ties the release to Canada’s national AI strategy, which named bias as a challenge to address. The connection to current law is looser. Ottawa’s recent online harms legislation does not prescribe specific fixes for model bias. It imposes a “Duty to Act Responsibly” on social media and AI chatbot services, which includes mitigating the risk of exposing users to harmful content, leaving the methods to the providers.
Why it matters: An open-source bias detector is only as consequential as the definition of bias baked into it, and that is where the hard questions live. Deciding what counts as neutral, especially on political framing, is an editorial judgment, not a purely technical one, and a tool that suggests neutral rewrites is making those calls at scale on behalf of whoever runs it. That is not a reason to dismiss it, but it is the thing organizations should inspect before adopting it. For Canadian firms, the more immediate value is regulatory positioning. With the online harms law setting a duty to act responsibly without specifying how, a documented bias-screening step becomes a way to show diligence against a standard that is otherwise left open. Vector being the source matters here too. A credible domestic research institution releasing this openly gives Canadian organizations a homegrown reference point rather than a foreign vendor’s black box, which fits the data-residency and sovereignty concerns that keep surfacing across the rest of this week’s stories.
Keep ahead of the curve – join our community today!
Follow us for the latest discoveries, innovations, and discussions that shape the world of artificial intelligence.

