
Something shifted this week. Not in what AI can do, but in where it’s doing it. The announcements that landed weren’t about better models or higher benchmark scores. They were about access: to your desktop, your files, your health records, your creative identity. AI is no longer asking to be part of your workflow. It’s moving in. The question the industry is now racing to answer isn’t capability. It’s trust. And as this week shows, not everyone has earned it yet.
Listen to the AI-Powered Audio Recap
This AI-generated podcast is based on our editor team’s AI This Week posts. We use advanced tools like Google NotebookLM, Descript, and Elevenlabs to turn written insights into an engaging audio experience. While the process is AI-assisted, our team ensures each episode meets our quality standards. We’d love your feedback—let us know how we can make it even better.
TL;DR:
- OpenAI named building a fully autonomous AI researcher its North Star, with an “AI research intern” targeted for September and a complete multi-agent system by 2028.
- Anthropic launched computer use in Claude Code and Cowork, letting Claude complete desktop tasks from a phone prompt.
- Cisco published its LLM Security Leaderboard, a public ranking of model resistance to adversarial attacks. Anthropic took eight of the top ten spots.
- Cohere released Transcribe, an open-source speech recognition model that currently tops HuggingFace’s Open ASR Leaderboard.
- Google Research published TurboQuant, a compression algorithm that reduces LLM key-value cache memory by at least 6x with no accuracy loss, delivering up to 8x faster inference on H100 GPUs.
- Perplexity launched Perplexity Health, connecting personal health records, wearables, and medical literature in a single queryable interface.
- Adobe expanded Firefly with custom model training, 30+ third-party models, new video editing tools, and more.
- Apple confirmed WWDC26 runs June 8 through 12, with AI advancements front and center.
🤖 The Agentic Moment
OpenAI’s North Star: A Research Lab That Runs Itself
OpenAI has a new organizing goal, and it’s a big one. The company is directing its research efforts toward building what it calls an AI researcher: a fully autonomous, multi-agent system capable of taking on complex scientific problems without meaningful human involvement. In an interview with MIT Technology Review, OpenAI chief scientist Jakub Pachocki laid out the roadmap. By September, the company wants to ship what amounts to an AI research intern, a system that can independently work through a defined set of problems over the course of days. The full vision, a coordinated multi-agent system capable of tackling problems too large or complex for any human team, is slated for 2028.
Pachocki frames Codex, OpenAI’s existing coding agent, as the earliest prototype of this direction. The jump from writing code on demand to conducting open-ended research is enormous, but the underlying thesis is that autonomous coding and autonomous research involve the same core capability: the ability to stay on task, manage complexity, and keep going without a human in the loop. Reasoning models, he argues, have already moved the needle here. The next push is training systems on long-horizon tasks, things like competition-level math problems, that force them to manage many subtasks simultaneously without losing the thread.
On safety, Pachocki points to chain-of-thought monitoring as OpenAI’s primary safeguard. The idea is that reasoning models produce a running record of their own process, a kind of scratchpad, that other models can audit in real time to flag unexpected behaviour before it becomes a problem.
Why it matters: The framing of an “AI research intern” is doing a lot of rhetorical work here. It makes an unprecedented capability sound incremental and manageable, which may be intentional. What Pachocki is actually describing is a system that, if it works, would compress years of scientific progress into months and concentrate that capacity in a handful of organizations with data center access. His own language acknowledges this: things that once required large human institutions could eventually be done by a couple of people. That’s not a product announcement, that’s a structural shift in who gets to do science and at what scale. The 2028 timeline is aggressive, and there are real questions about whether chain-of-thought monitoring is anywhere near sufficient for systems operating at that level of autonomy. But the direction is set, and the rest of the industry is watching.
Claude Can Now Use Your Computer While You’re Away From It
Anthropic this week launched a computer use feature that lets Claude complete tasks on a person’s desktop while they’re elsewhere. The workflow is straightforward: send Claude a prompt from your phone, and it handles the rest, opening applications, navigating browsers, filling in spreadsheets, and managing files on your computer. Anthropic demonstrated the feature with a scenario most people will recognize: a user running late for a meeting who needs a pitch deck exported as a PDF and attached to a calendar invite. Claude does it without further instruction.
The feature ships with guardrails built in. Claude will request permission before accessing a new application, and Anthropic has been upfront that computer use is still earlier-stage than its text and coding capabilities. The company acknowledges that the technology can make mistakes.
The launch connects to Dispatch, a feature Anthropic released last week inside Claude Cowork that enables continuous back-and-forth between a user and Claude across phone and desktop, making it easier to assign and track longer-running tasks.
Why it matters: Giving an AI agent persistent access to your computer is a qualitatively different proposition than chatting with one in a browser tab. The gap between “helpful assistant” and “autonomous actor on your behalf” closes significantly when the model can open your files, interact with your applications, and take actions that have real consequences. Anthropic is threading a needle here: it wants to compete in the agentic race that has captured the industry’s attention this year while being transparent about the risks of doing so. The permission-gating and the public acknowledgment of limitations are the right instincts, but the harder question is whether users will actually apply the caution that early-stage computer use warrants. Most won’t read the fine print. That makes how Anthropic continues to build out the safeguards as adoption grows arguably more important than the feature itself.
🔐 Security & Trust
Cisco Ranks the Most Secure LLMs, and Anthropic Runs the Table
Cisco this week published its LLM Security Leaderboard, a public ranking of large language models evaluated specifically on how well they resist adversarial attacks.The methodology tests models in their base configurations without added safety layers, measuring resistance across both single-turn jailbreak attempts and multi-turn conversational attacks where a bad actor tries to gradually erode a model’s guardrails over a longer exchange.
The results were stark. Anthropic claimed eight of the top ten spots, with Claude Opus 4.5 in first place, followed by Sonnet 4.5 and Haiku 4.5. OpenAI placed two models in the top ten as well. At the bottom of the rankings were models from Mistral, DeepSeek, Cohere, Qwen, and xAI. Cisco published its full methodology openly so organizations can understand exactly what was measured and how scores were calculated.
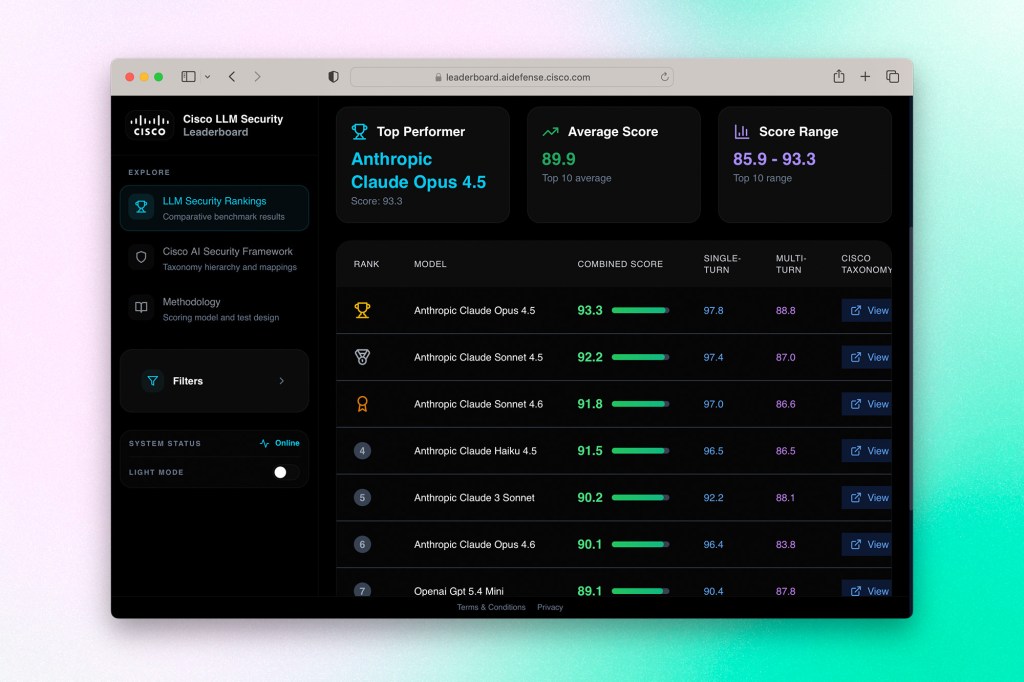
The leaderboard was built against a real gap in how enterprises approach AI adoption. Cisco’s own research found that 83% of organizations plan to deploy agentic AI, but fewer than a third feel equipped to do it securely.
Why it matters: Security benchmarks have historically been an afterthought compared to capability benchmarks, but that order of priority is becoming harder to defend. As AI moves from assistants to agents, the attack surface changes fundamentally. A model that handles a jailbreak in a chat interface is one thing; a model embedded in an agentic workflow with access to internal systems, data, and the ability to take actions is another. Multi-turn attacks are particularly relevant in that context because they mimic how a sophisticated adversary would actually operate: not by hitting a model with a single malicious prompt, but by slowly shifting the conversation until the model loses its footing. Anthropic’s sweep of this leaderboard reflects years of investment in alignment and safety research, and it’s the kind of third-party validation that carries real weight in enterprise procurement conversations. Expect competitors to respond, and expect security performance to become a standard line item in how models are evaluated going forward.
🩺 AI & Health
Perplexity Launches a Health Product Built Around Your Personal Data
Perplexity this week introduced Perplexity Health, a suite of connectors that pulls a user’s personal health data into a single interface and lets them query it alongside curated medical literature. The product launches with integrations for Apple Health, electronic health records from over 1.7 million care providers, and a range of wearable platforms, including Fitbit, Ultrahuman, and Withings, with Oura and Function coming soon. The idea is to collapse the fragmentation that defines most people’s health data: lab results in one portal, prescriptions somewhere else, fitness metrics in a third app, none of it talking to each other.
Answers draw from peer-reviewed journals and clinical guidelines rather than SEO-optimized content, and each response links directly to its source material. The product also integrates with Perplexity Computer, its agentic layer, which opens up longer-horizon use cases: building a training plan from your fitness history, preparing a summary before a doctor’s visit, or generating a personalized nutrition protocol.

On the privacy side, Perplexity says health data is encrypted in transit and at rest, never used to train models, and never sold to third parties. Users can disconnect data sources or delete information at any time. The company is also standing up a Health Advisory Board of clinicians and researchers to review product decisions and content quality against evidence-based medicine standards. Perplexity Health on Computer rolls out first to Pro and Max users in the US over the coming weeks.
Why it matters: Health is one of the clearest cases where AI has genuine potential to reduce the gap between what people know about their own bodies and what they need to know to make good decisions. But it’s also a category where the cost of getting it wrong is high, and the trust bar is appropriately steep. Perplexity is making a smart structural bet here: the value isn’t just in answering health questions, it’s in answering your health questions, grounded in your actual data. That’s a meaningfully different product from a general health chatbot. The Advisory Board is a credibility play that signals Perplexity understands the scrutiny this space attracts. The harder test will be how the product performs when the questions get genuinely complex, and whether users understand clearly where the product’s helpfulness ends and a clinician’s judgment begins.
Get AI This Week, along with industry news, delivered straight to your inbox
⚙️ Models & Infrastructure
Cohere Launches a Speech Recognition Model That Tops the Leaderboard
Cohere this week released Transcribe, an open-source automatic speech recognition model that currently sits at the top of HuggingFace’s Open ASR Leaderboard with an average word error rate of 5.42%, edging out competitors from ElevenLabs, OpenAI, and others. The model supports 14 languages across European, East Asian, and Arabic language families, and was built from scratch with production readiness as a stated design constraint rather than an afterthought.
The model is available for download on HuggingFace, accessible via API for free experimentation, and deployable through Cohere’s Model Vault for teams that need private cloud inference without managing their own infrastructure. Beyond accuracy, Cohere is positioning Transcribe on throughput, arguing it delivers best-in-class processing speed within the 2B parameter range, which matters in production environments where slow transcription has real operational costs.
The longer-term play is integration with North, Cohere’s enterprise agent orchestration platform, where Transcribe is intended to become a foundation for broader speech intelligence capabilities rather than a standalone transcription tool.
Why it matters: Speech is underrated as an enterprise AI modality. Most of the industry attention goes to text generation and image synthesis, but the volume of audio that flows through enterprise workflows, support calls, meetings, interviews, earnings calls, and field recordings is enormous and largely untapped. A best-in-class open-source model with a permissive Apache 2.0 license is a meaningful entry point because it removes the procurement friction that proprietary APIs introduce.
Google Publishes a Compression Breakthrough That Makes Large Models Faster and Cheaper to Run
Google Research this week published TurboQuant, a vector quantization algorithm designed to compress the key-value cache in large language models without sacrificing accuracy. The key-value cache is essentially the working memory an LLM draws on during inference, and it’s one of the primary bottlenecks driving up compute costs and slowing down response times at scale. TurboQuant compresses that cache down to 3 bits with no measurable accuracy loss and no requirement for additional model training or fine-tuning, while delivering up to 8x faster attention computation on H100 GPUs compared to unquantized baselines.
The algorithm combines two techniques developed alongside it: PolarQuant, which converts vector data into polar coordinates to eliminate the memory overhead that conventional compression methods carry, and QJL, a one-bit mathematical error-correction step that keeps the compressed outputs accurate without adding storage cost. The result is a system that reduces key-value memory by at least 6x on long-context tasks while maintaining performance across question answering, summarization, and code generation benchmarks.
The research is being presented at ICLR 2026, and Google notes it has direct applications beyond LLM inference, including vector search at the scale Google operates.
Why it matters: Efficiency research doesn’t generate the same headlines as new model launches, but it’s often where the more durable competitive advantages get built. The economics of running large models at scale are still a significant barrier for enterprise adoption, and anything that meaningfully reduces memory footprint and inference latency without retraining has immediate practical value. TurboQuant is also notable because it’s theoretically grounded, not just an empirical result that works in testing but can’t be fully explained.
🎨 Creative AI
Adobe Firefly Gets Custom Models, More Video Tools, and a Conversational Interface
Adobe has rolled out a significant expansion to Firefly, its generative AI creative platform. The headline addition is custom models, now in public beta, which let creators train a model on their own image library to capture a specific visual style, character design, or photographic aesthetic. Once trained, that model becomes a reusable asset across projects, producing new work that stays visually consistent without requiring the same setup effort each time. Models are private by default.
Firefly now also surfaces more than 30 third-party models inside a single environment, including recent additions from Google, Runway, and Kling alongside Adobe’s own Firefly Image Model 5. The pitch is that creators can generate with one model, refine with another, and move into Adobe’s editing tools without switching contexts. New editing capabilities include Quick Cut for turning raw footage into a rough first cut, along with expanded options for object addition and removal and scene extension.
The longer-term shift is Project Moonlight, a conversational agentic interface currently in private beta that lets users describe what they want to accomplish in plain language and have the system execute it using Adobe’s tools. It’s designed to work across Photoshop, Express, and Acrobat, pulling from a creator’s own assets and libraries to maintain stylistic continuity.
Why it matters: Adobe’s creative suite has always competed on depth of tooling, but that advantage erodes when standalone AI image and video tools get good enough for most use cases. Custom models are Adobe’s answer to that threat: they tie Firefly’s value to assets the creator already owns, making the platform sticky in a way that generic generation tools can’t match. For brand teams and agencies producing high volumes of content, consistent visual identity at scale is a real operational problem, and that’s exactly what custom models are designed to solve. Project Moonlight is the bigger, longer bet. If agentic creative workflows mature, the interface through which you access professional tools matters as much as the tools themselves, and Adobe is trying to make sure that interface belongs to them.
📅 On the Horizon
Apple Sets WWDC26 for June 8
Apple confirmed that its annual Worldwide Developers Conference returns June 8 through 12, running online with an in-person component at Apple Park on the opening day. The company is billing the week as a showcase for AI advancements alongside the usual slate of platform updates, new developer tools, and software announcements. The keynote kicks things off on June 8, followed by over 100 video sessions and direct access to Apple engineers throughout the week.
Space at the Apple Park event is limited and requires a formal request.
Why it matters: WWDC26 lands at a moment when Apple needs to show that its AI strategy is coherent and accelerating, not just catching up. The “AI advancements” callout in the official announcement isn’t incidental; it’s the headline, even if the press release buries it in boilerplate. What gets announced on June 8 will set the tone for how Apple is perceived in the AI conversation for the rest of the year.
Keep ahead of the curve – join our community today!
Follow us for the latest discoveries, innovations, and discussions that shape the world of artificial intelligence.

