
This week’s edition covers a lot of ground, but a few threads run through it. AI is finding vulnerabilities faster than the security industry can patch them, solving math problems that stumped humans for 80 years, and making it possible to ship software products at a pace that would have been unthinkable two years ago. At the same time, the question of who controls AI, who benefits from it, and who is accountable when it causes harm is getting harder to ignore. The Pope weighed in. So did a new class of marketplace builders trying to figure out what expertise is worth in a world where generic AI handles the baseline. Busy week.
Listen to the AI-Powered Audio Recap
This AI-generated podcast is based on our editor team’s AI This Week posts. We use advanced tools like Google NotebookLM, Descript, and Elevenlabs to turn written insights into an engaging audio experience. While the process is AI-assisted, our team ensures each episode meets our quality standards. We’d love your feedback—let us know how we can make it even better.
TL;DR
- Anthropic released Claude Opus 4.8 with dynamic workflows for large-scale autonomous coding tasks, a new effort control that lets users manage depth versus speed, and an alignment profile the company says is on par with its best-aligned model; a general Mythos-class release is now weeks away.
- Pope Leo XIV issued a 200-page encyclical calling AI the defining challenge of the era and demanding external governance.
- Anthropic’s Project Glasswing found 10,000+ vulnerabilities in critical software, but the patch ecosystem can’t keep up.
- Perplexity open-sourced Bumblebee, a supply-chain scanner with MCP coverage built in.
- Meta launched Forum, a Reddit-style app built on Facebook Groups with an AI-powered search layer.
- Capafy opened a closed-source marketplace where domain experts can monetize AI skills without exposing their methodology.
- OpenAI’s reasoning model disproved an 80-year-old geometry conjecture that stumped human mathematicians for decades.
🤖 New Models
Anthropic Releases Claude Opus 4.8 with Dynamic Workflows and Effort Control
Anthropic has released Claude Opus 4.8, an incremental upgrade to its flagship model that ships with benchmark improvements across coding, reasoning, and agentic tasks, and is available at the same price as its predecessor. The release comes with a handful of features that collectively point toward how Anthropic is thinking about long-running, large-scale AI work.
The most practically significant addition is dynamic workflows in Claude Code, currently in research preview. The feature lets Claude plan a task, spin up hundreds of parallel subagents within a single session, and verify outputs before surfacing results. The stated example is codebase-scale migrations across hundreds of thousands of lines of code, completed start to finish with the existing test suite as the quality bar. A separate effort control is now available across claude.ai and Cowork, letting users choose how deeply the model thinks before responding, trading response speed and rate limit consumption against output quality. Fast mode for Opus 4.8 is also now three times cheaper than it was for previous models.
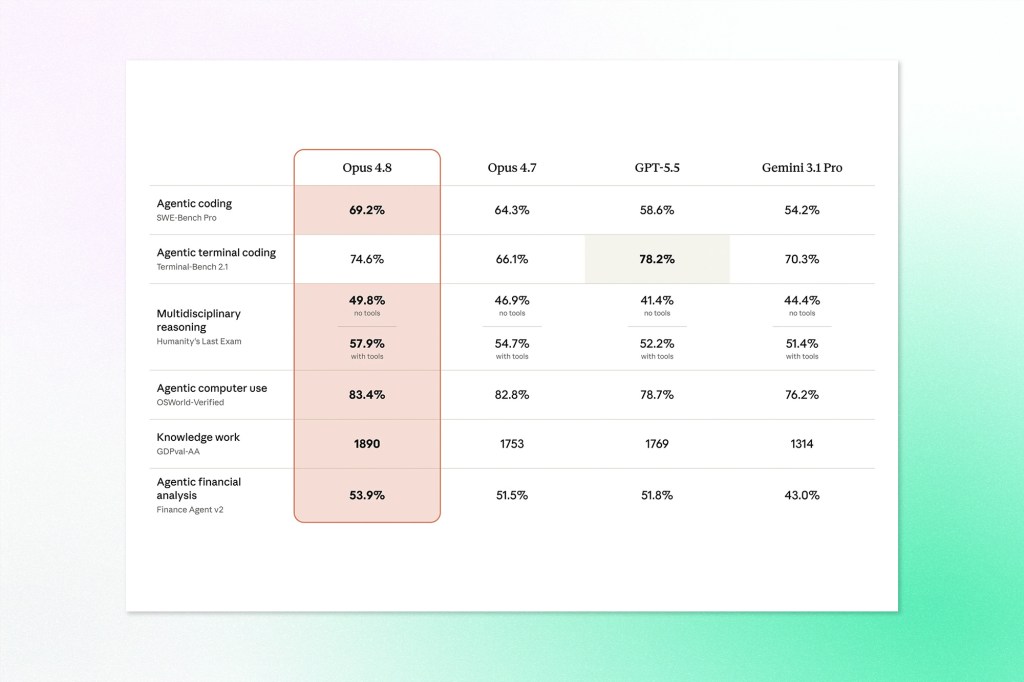
On the alignment side, Anthropic’s internal assessment found Opus 4.8 to be around four times less likely than its predecessor to let flaws in its own code go unremarked. The team noted improvements in what they describe as prosocial behaviour, including stronger support for user autonomy. Misaligned behaviour rates are reported as similar to Claude Mythos Preview, which Anthropic considers its best-aligned model.
Anthropic also signalled that a general release of Mythos-class models is expected within weeks, pending completion of stronger safeguards.
Why it matters: The effort control is a small feature with a larger implication. Giving users direct control over how hard the model works is an acknowledgment that not every task warrants the same depth of reasoning, and that rate limits and cost are real constraints people want to manage themselves. That’s a more honest model of how people actually use these tools than defaulting to maximum effort across the board. The dynamic workflows feature is the more consequential bet: if Claude Code can reliably execute large migrations autonomously and verify its own output, the category of work that requires continuous human oversight shrinks meaningfully. Whether it holds up in practice at the scale being described is the question early adopters will answer quickly.
🏛️ Policy & Governance
The Vatican Enters the AI Debate, and It Has Notes for the Industry
Pope Leo XIV released his first encyclical on Monday, titled “Magnifica Humanitas,” framing artificial intelligence as the defining challenge of the current era and calling for robust legal frameworks, independent oversight, and a fundamental shift in who AI is built to benefit. The 200-page document was presented at the Vatican alongside Anthropic co-founder Chris Olah, a pairing that drew both attention and criticism, given Anthropic’s ongoing legal dispute with the Trump administration over military use of its technology.
The encyclical’s central argument is structural: technology designed and governed by a small elite cannot serve the common good by definition. Leo repeatedly targeted the concentration of data and decision-making power in private hands, warning that such concentration tends toward opacity, manipulation, and the erosion of democratic processes. On warfare specifically, he declared that entrusting irreversible lethal decisions to AI systems is impermissible, called existing just war theory outdated in light of current technology, and demanded clear accountability chains for AI-assisted military strikes.
The document is deliberately rooted in Catholic social teaching, signed on the 135th anniversary of Rerum Novarum, the landmark 1891 encyclical that addressed worker dignity and the limits of capital during the Industrial Revolution. Leo XIV draws a direct parallel, positioning AI as a comparable civilizational inflection point. Olah, for his part, welcomed the criticism, calling for more moral voices outside the industry that “the incentives cannot bend.”
Why it matters: Read as theology, the encyclical is unremarkable. Read as a political intervention, it is well-timed and deliberately targeted. The argument that industry-defined ethics cannot substitute for external governance has been made before, but rarely from a platform this visible or with this much historical framing behind it. Leo signed the document on the anniversary of Rerum Novarum for a reason: he is explicitly positioning AI regulation as the labour rights question of this century, and inviting the same long arc of institutional response. That framing gives regulators and civil society something to work with beyond technical white papers and congressional testimony. The rhetorical ground has shifted, even if the law hasn’t.
🔒 Security & Infrastructure
Perplexity Open-Sources Bumblebee, a Supply-Chain Security Scanner for Developer Machines
Perplexity has released Bumblebee as an open-source tool, giving any security team access to the scanner it uses internally to protect the developer systems behind its own products. The tool is designed to answer a specific question when a supply-chain vulnerability is disclosed: which developer machines in your organization are actually exposed?
Bumblebee runs on developer laptops rather than repositories or build pipelines, covering language package managers, AI agent configurations (including MCP), editor extensions for VS Code-family tools, and browser extensions across Chromium and Firefox. It operates as a read-only scanner, pulling from metadata files like lockfiles and manifests rather than invoking package managers directly. That distinction matters because tools like npm can execute install scripts automatically, which is how many recent supply-chain attacks have propagated. A scanner that calls npm to check for a bad package could trigger the attack in the process. Bumblebee avoids that entirely.
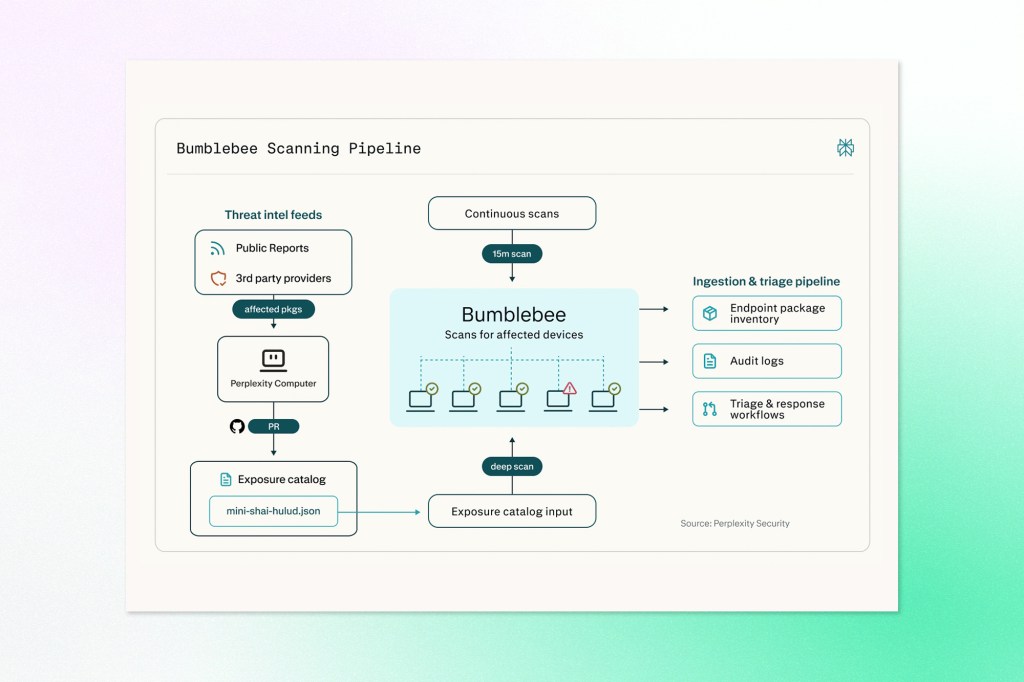
Internally, Perplexity uses it as part of a layered workflow: Perplexity Computer monitors for emerging threats and drafts structured catalogue updates, humans review and merge them, and Bumblebee then scans endpoints against the updated catalogue. The tool supports three scan profiles ranging from routine laptop checks to deep sweeps during active incidents. It’s available now as a Go project for macOS and Linux.
Why it matters: The MCP coverage is the detail worth watching. As AI agent tooling becomes standard in developer environments, MCP configurations represent a new and largely unmonitored attack surface on developer machines. Most existing security tooling wasn’t built with that surface in mind. Bumblebee filling that gap, and doing so as open-source infrastructure, means the broader security community can build on it rather than waiting for vendors to catch up. The move also signals that AI companies with sophisticated internal tooling are starting to recognize that open-sourcing security infrastructure builds trust in a way that press releases don’t.
Anthropic’s Project Glasswing Has Found Over 10,000 Vulnerabilities in Critical Software
One month into Project Glasswing, Anthropic and its roughly 50 partners have used Claude Mythos Preview to identify more than 10,000 high- or critical-severity vulnerabilities across some of the most widely depended-upon software in the world. Several partners report that their rate of bug discovery has increased by more than a factor of ten. Cloudflare alone found 2,000 bugs across its critical systems, 400 of them high- or critical-severity, with a false positive rate that its team considers better than human testers.
Anthropic has also been running Mythos Preview across more than 1,000 open-source projects independently. Of the vulnerabilities assessed so far by external security firms, 90.6% have been confirmed as valid, and 62.4% were rated high- or critical-severity. One confirmed finding involved wolfSSL, a cryptography library used by billions of devices, where Mythos constructed a working exploit that would have allowed an attacker to forge certificates and impersonate legitimate websites. That vulnerability has since been patched.

Mythos Preview remains unreleased to the public. Anthropic says no company, including itself, has yet developed safeguards strong enough to prevent misuse of models at this capability level. The bottleneck in the project has shifted entirely: finding vulnerabilities is no longer the hard part. Triaging, disclosing, and patching them is. Some open-source maintainers have asked Anthropic to slow its disclosure rate because they lack the capacity to keep up.
To help the broader ecosystem, Anthropic has released Claude Security in public beta for Enterprise customers, launched a Cyber Verification Program for legitimate security researchers, and is making the scanning tools, harnesses, and skills developed during Glasswing available to qualifying security teams.
Why it matters: Project Glasswing is the clearest demonstration yet that AI capability and AI safety can be in genuine tension even when the application is unambiguously defensive. Mythos Preview is finding real vulnerabilities at a scale and speed that human researchers cannot match, but the same capability that makes it useful for defence makes it dangerous in other hands. Anthropic’s decision to withhold public release while selectively deploying it through vetted partners is a live experiment in what responsible capability deployment actually looks like under pressure. The more uncomfortable implication sits underneath all of it: the patch ecosystem was not built for this volume. The security industry’s human infrastructure is now the limiting factor, and that gap will only widen as other labs develop comparable models.
🛠️ Products & Platforms
Meta Launches Forum, a Reddit-Style App Built on Facebook Groups
Meta has released a new standalone app called Forum, positioning it as a destination for deeper community discussions built on top of existing Facebook Groups infrastructure. Users sign in with their Facebook accounts, and their groups, profiles, and activity carry over automatically. Posts can be made under a nickname, and anything shared in Forum also appears in the corresponding Facebook Group.
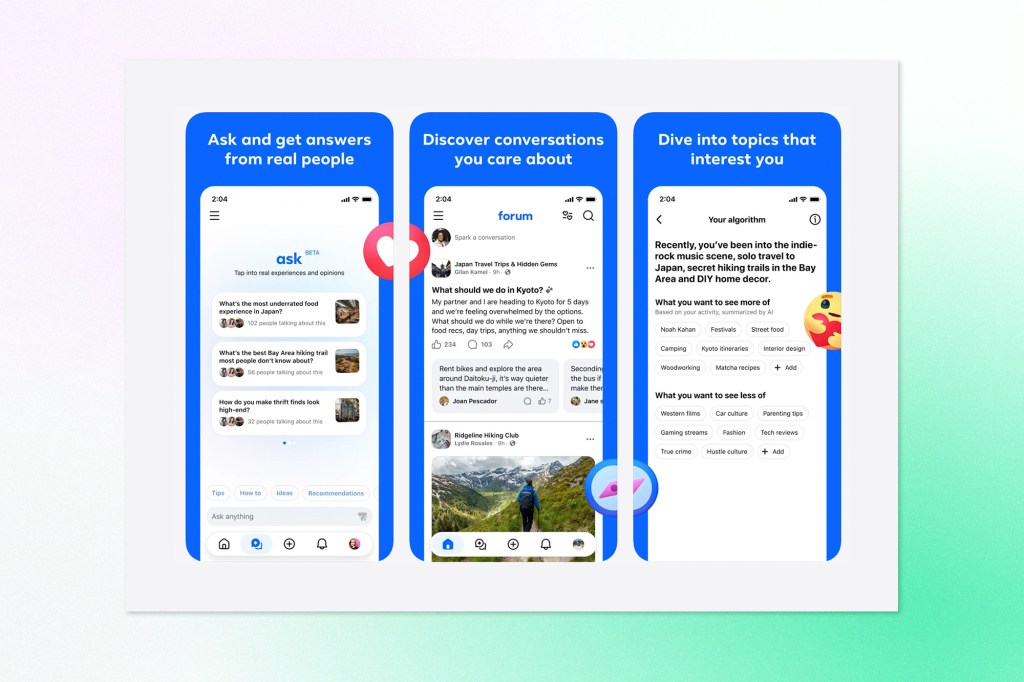
The app’s defining feature is an AI-powered “Ask” tab that pulls answers from conversations across multiple groups, letting users surface relevant discussions without manually searching each community. There’s also an AI assistant for group admins to help with moderation and content management.
Meta CEO Mark Zuckerberg has signalled this is part of a larger product push, telling employees that AI-driven efficiencies have made it possible to ship many more apps than the company has historically. Forum is the second new standalone release from Meta in recent weeks, following Instants, a disappearing photo app with clear parallels to Snapchat and BeReal.
Why it matters: Forum is less interesting as a product than as a signal about how Meta is thinking about AI. The “Ask” tab isn’t just a feature; it’s a proof of concept for using AI to make large, messy social archives actually useful. Facebook Groups collectively hold an enormous volume of niche, real-world knowledge that has historically been buried and unsearchable. If Meta can surface that effectively, Forum doesn’t need to beat Reddit on culture or community; it just needs to be more useful. The broader “50 apps” ambition also tells you something about how Meta expects AI to change the economics of product development. Shipping fast and thin, then iterating, only works if the underlying AI layer is doing real work.
Capafy Launches a Closed-Source Marketplace for AI Agent Skills
A new platform called Capafy is trying to solve a structural problem in the agent skills ecosystem: the people who build the most valuable skills have little incentive to share them, because publishing openly means giving the methodology away for free. Capafy’s answer is to keep skill logic server-side and hidden. Buyers get the output when they run a skill; they never see the underlying code, reasoning, or methodology. Creators set their own price and get paid per execution.
The platform targets domain experts rather than developers: an HR professional who knows which resume signals actually lead to interviews, a video creator who has refined what keeps attention in the first few seconds of a clip, a researcher with a sourcing process that consistently outperforms generic search. The argument is that this kind of calibrated, context-specific know-how is what separates expert output from what a default agent produces, and that it currently sits in private folders because there’s no viable way to monetize it without exposing it. Skills on Capafy run across Claude Code, Codex, and OpenClaw without installation.
The broader marketplace for agent skills has expanded quickly, with several open-source registries now operating on the assumption that skills are public and forkable. Capafy takes the opposite position, treating skill logic as intellectual property that can be licensed and executed without ever being transferred.
Why it matters: The open-source assumption baked into most skill ecosystems works well for general-purpose tools but breaks down for anything that derives its value from proprietary judgment. Capafy is essentially proposing a middle layer between “give it away” and “keep it private forever,” one that lets expertise circulate economically without being commoditized on contact. Whether that model holds depends on whether buyers are willing to pay per use for outputs they can’t audit or replicate. That’s a different trust relationship than software licensing, and it will be tested quickly now that the platform is live.
Ready to explore what AI can do for your organization?
🧠 Research & Capability
OpenAI’s AI Solves an 80-Year-Old Geometry Problem, and Mathematicians Are Taking Notice
An internal OpenAI reasoning model has produced the first AI-generated mathematical proof that experts say would merit publication in a top mathematics journal on its own merits. The result involves the “unit distance” problem, a geometry conjecture posed by mathematician Paul Erdős in 1946 that asks, for any number of points on a plane, how many pairs can be positioned exactly one unit apart. Erdős believed he had found the optimal approach, and for eight decades, no one proved him wrong or did better. The OpenAI model did both: it found a counterexample, disproving the conjecture.
The approach the model took was not one that human mathematicians had seriously pursued. Rather than working within the two-dimensional framework, it constructed a higher-dimensional lattice with specific mathematical symmetries, then mapped it back down to the plane. The tools it used were not new, but their application here appears to be. Cambridge mathematician Timothy Gowers, one of several experts privately consulted by OpenAI to verify the result, wrote that no previous AI-generated proof had come close to this standard.
What the outside mathematicians found most striking was the model’s willingness to pursue a tedious, unrewarding path with no early signal that it would pay off. Human researchers, largely convinced Erdős was right, had spent more energy trying to prove the conjecture than challenge it. An LLM doesn’t experience that cost the same way. The result has already been extended by mathematician Will Sawin, who improved on the AI’s construction after the fact.
Experts were careful to note the human effort involved in verifying, cleaning up, and contextualizing the output, and several flagged that the model failed to credit closely related ideas already in the literature, something one mathematician described as professional malpractice if a human had done it.
Why it matters: This result is less significant for the specific problem solved than for what it reveals about where AI is useful in mathematics. The unit distance problem fell not because the AI had a brilliant new idea, but because it was willing to pursue an unglamorous approach that human experts had dismissed or ignored. That’s a different kind of capability than breakthrough insight, but it may be more broadly applicable than it first appears. If there are many unsolved problems where the solution was always within reach of existing tools, but nobody tried the obvious, tedious path, AI has a structural advantage in finding them. The academic norms question is also not trivial: a research tool that doesn’t credit prior work will create real friction as these results enter peer review.
Keep ahead of the curve – join our community today!
Follow us for the latest discoveries, innovations, and discussions that shape the world of artificial intelligence.

