
This week’s news had a clear center of gravity: enterprises are no longer debating whether to deploy AI agents; they’re debating how much control to hand over. Anthropic, Salesforce, Writer, and Pinecone all shipped infrastructure that moves agents further from human supervision — while Anthropic and OpenAI simultaneously announced joint ventures to embed engineers inside mid-market companies, signalling that the next competitive frontier is implementation, not capability. A WP Engine report found 72% of agencies are already redesigning for a dual audience of humans and machines. Meta and Google DeepMind published research that makes capable AI systems cheaper and faster to build. And Deezer put hard numbers on something the music industry has been circling for months: AI-generated content isn’t flooding platforms because anyone is listening to it. It’s flooding platforms because someone is getting paid when it does.
Listen to the AI-Powered Audio Recap
This AI-generated podcast is based on our editor team’s AI This Week posts. We use advanced tools like Google NotebookLM, Descript, and Elevenlabs to turn written insights into an engaging audio experience. While the process is AI-assisted, our team ensures each episode meets our quality standards. We’d love your feedback—let us know how we can make it even better.
TL;DR
- Anthropic shipped dreaming, outcomes, and multiagent orchestration for Claude Managed Agents, giving agents the ability to self-improve between sessions, evaluate their own outputs, and parallelize complex work
- Salesforce extended its Agent platform into back-office operations — procurement, finance, supply chain — with Agentforce Operations.
- Writer added event-based triggers so AI agents fire workflows automatically when a business signal is detected, no human prompt required.
- Anthropic and OpenAI each announced enterprise AI joint ventures on the same day, both targeting mid-market companies using the forward-deployed engineer model.
- Pinecone launched Nexus, a knowledge engine that compiles task-specific information before agents need it, along with KnowQL, a declarative query language for agent knowledge retrieval
- Deezer reported that 44% of new music uploaded to its platform is AI-generated.
- Google DeepMind’s Vision Banana demonstrated that image generation pretraining can replace specialist vision architectures across segmentation, depth estimation, and more.
- Meta’s Autodata framework uses AI agents to iteratively generate and improve their own training data, treating data creation as an optimization problem.
- A WP Engine agency report found 72% of agencies have redesigned for AI, with a widening gap between those embedding it into core services and those still experimenting.
🤖 The Enterprise Agentic Push
Anthropic Adds Self-Improving Memory and Multiagent Orchestration to Claude Managed Agents
Anthropic has shipped three significant updates to its Claude Managed Agents platform. The first, called dreaming, is a scheduled process that reviews past agent sessions, extracts patterns across them, and updates memory so agents improve between runs rather than starting fresh each time. Dreaming surfaces recurring mistakes, workflows agents converge on, and preferences shared across a team — things no single session can see on its own. Developers can let it update memory automatically or review changes before they land.
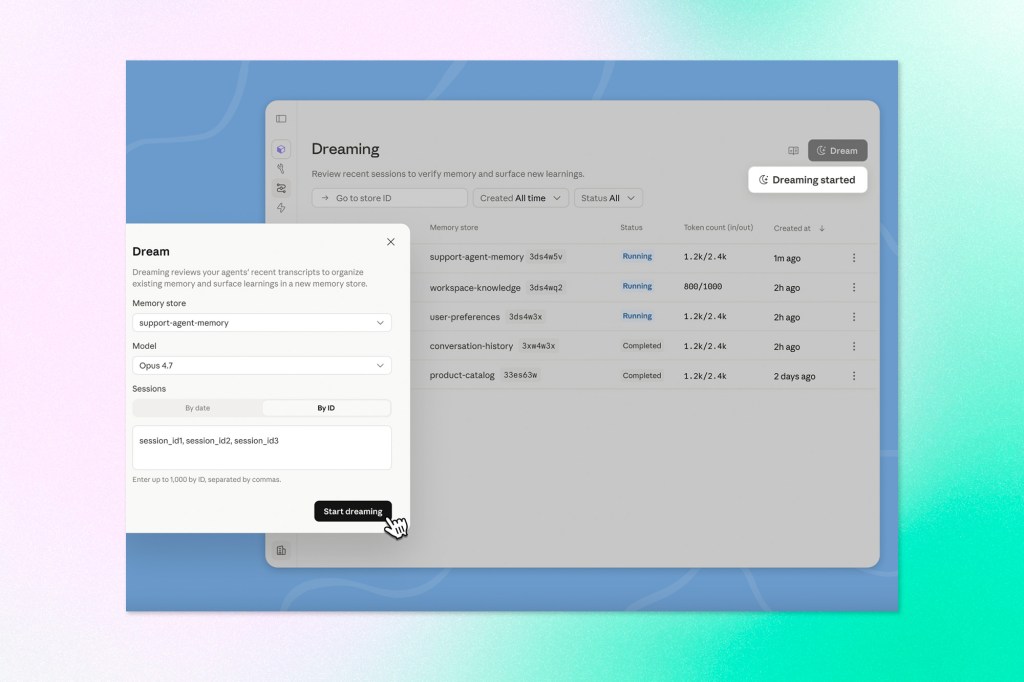
The second update, outcomes, lets developers define a rubric describing what success looks like. A separate grader evaluates the agent’s output against that rubric in its own context window, isolated from the agent’s reasoning, and sends the agent back for another pass if the output doesn’t clear the bar. Anthropic reports up to 10 percentage point improvements in task success over standard prompting, with gains of 8.4% on document generation and 10.1% on presentation files. The third update enables multiagent orchestration, where a lead agent breaks complex work into pieces and delegates to specialist subagents running in parallel on a shared filesystem. Every step is traceable in the Claude Console.
Early users include Harvey for long-form legal drafting, Netflix for parallel log analysis across hundreds of builds, and Wisedocs for document quality review, which cut review time by 50%.
Why it matters: Dreaming is the most architecturally interesting piece here. Most agent memory implementations are session-level at best — the agent learns within a run but resets afterward. A system that reviews sessions, extracts cross-agent patterns, and continuously refines memory starts to look less like a tool and more like an institutional knowledge base that compounds over time. Combined with outcomes-based self-correction and parallel multiagent execution, these updates address three of the most common reasons production agents underperform: they don’t learn, they can’t self-evaluate, and they serialize work that should run in parallel.
Salesforce brings agentic AI to the back office with Agentforce Operations
Salesforce has launched Agentforce Operations, extending its AI agent platform beyond customer-facing workflows into the back-office processes that typically sit behind them — procurement, finance, supply chain, compliance, and onboarding. The pitch is that most enterprise automation stalls at system boundaries, routing work to humans rather than completing it. Agentforce Operations is built to cross those boundaries: specialized agents extract data from documents, validate compliance, chase approvals, and update records across disconnected systems without human handoffs. Salesforce claims the approach cuts cycle times by 50 to 70% and reduces manual data entry by 80%. Businesses can convert existing process documents into operational blueprints in minutes, or pull from a library of 30 pre-built templates covering common workflows like invoice auditing and purchase order rescheduling. The product is generally available now.
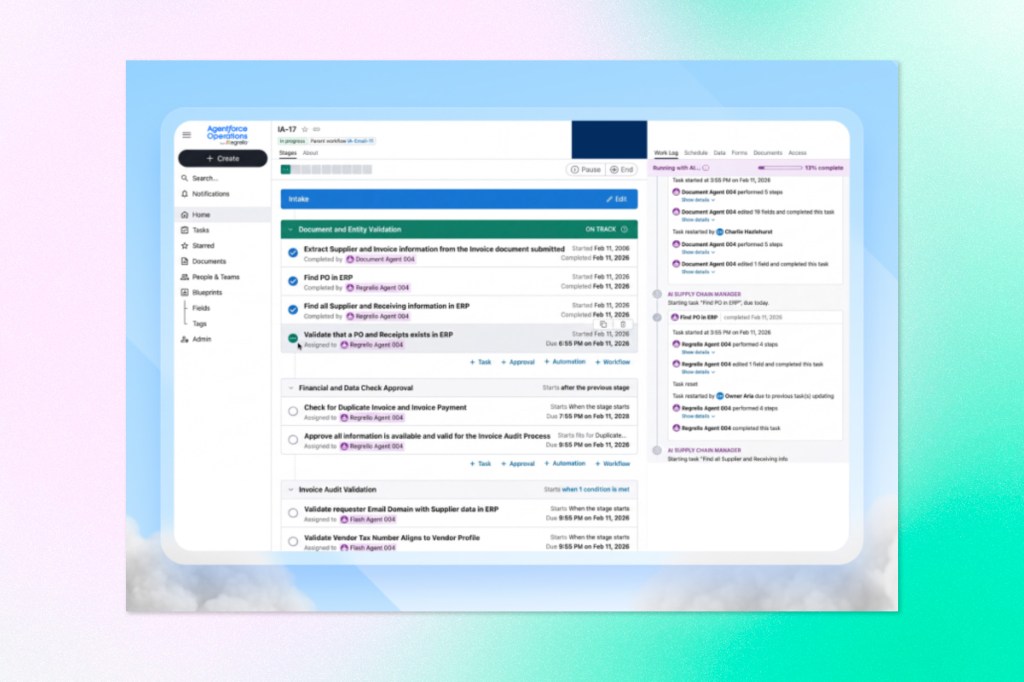
Why it matters: The front office has had AI agents for a while. The back office is where the bottlenecks actually live, and that’s what Salesforce is targeting here. Enterprises that have already deployed Agentforce for customer service or sales now have a path to connect those experiences to the operational layer underneath — without rebuilding their existing systems. The more interesting design choice is the audit trail. Back-office processes in regulated industries fail automation initiatives not because the technology isn’t there, but because compliance requirements demand accountability at every step. If Agentforce Operations delivers on the transparency claims, that removes one of the more durable objections to agentic AI in finance, insurance, and healthcare.
Anthropic and OpenAI Both Launch Enterprise AI Joint Ventures on the Same Day
On Monday, Anthropic announced a joint venture with Blackstone, Hellman & Friedman, and Goldman Sachs to deploy Claude across mid-sized enterprises, such as community banks, regional health systems, and mid-sized manufacturers, that want AI in their core operations but lack the internal resources to build and run it. The model is hands-on: Anthropic applied AI engineers work directly alongside customers to identify where Claude fits, build custom solutions, and stay involved over time. The venture is valued at $1.5 billion, with $300 million committed each from Anthropic, Blackstone, and Hellman & Friedman, and additional backing from Apollo Global Management, General Atlantic, GIC, Leonard Green, and Sequoia Capital.
Hours before that announcement, Bloomberg reported that OpenAI is finalizing a parallel venture called The Development Company, operating at considerably larger scale: $4 billion raised from 19 investors against a $10 billion valuation, with backers including TPG, Brookfield, Advent, and Bain Capital. The structural logic is the same: alternative asset managers invest, their portfolio companies become a built-in customer pipeline, and the venture captures value from the resulting contracts. Both ventures lean into the forward-deployed engineer model that Palantir made famous, embedding technical staff directly in client operations.
Why it matters: The timing is almost certainly not coincidental, and the symmetry between the two announcements is telling. Both labs have saturated the large-enterprise market through systems integrators and are now competing for the next tier down: mid-market companies with real AI budgets but no deployment capacity. The joint venture structure is clever because it solves a distribution problem and a capital problem simultaneously: investors bring deal flow through their portfolios, and the venture funds the engineering headcount needed to deliver. For the private equity firms involved, it’s a way to drive AI adoption across holdings while capturing upside from the contracts that follow. The race to own enterprise implementation at scale is now as competitive as the model race itself.
Writer Launches Event-Based Triggers so AI Agents Act Without Being Asked
Writer has added event-based triggers to its Agent platform, enabling AI agents to monitor business tools like Gmail, Gong, Google Calendar, Google Drive, SharePoint, Slack, and automatically fire workflows when something happens, without a human initiating anything. Writer found that, as enterprise customers built out playbooks, the humans responsible for triggering them became the bottleneck. A marketing brief landing in a Google Drive folder, for example, can now kick off a full cascade: research assembled, assets generated, copy drafted, deliverables staged for review, all before anyone opens a chat window. The release also includes an Adobe Experience Manager connector, a governance package covering bring-your-own encryption keys and connector permission profiles, and a Datadog observability plugin that logs every LLM request and response as structured events.
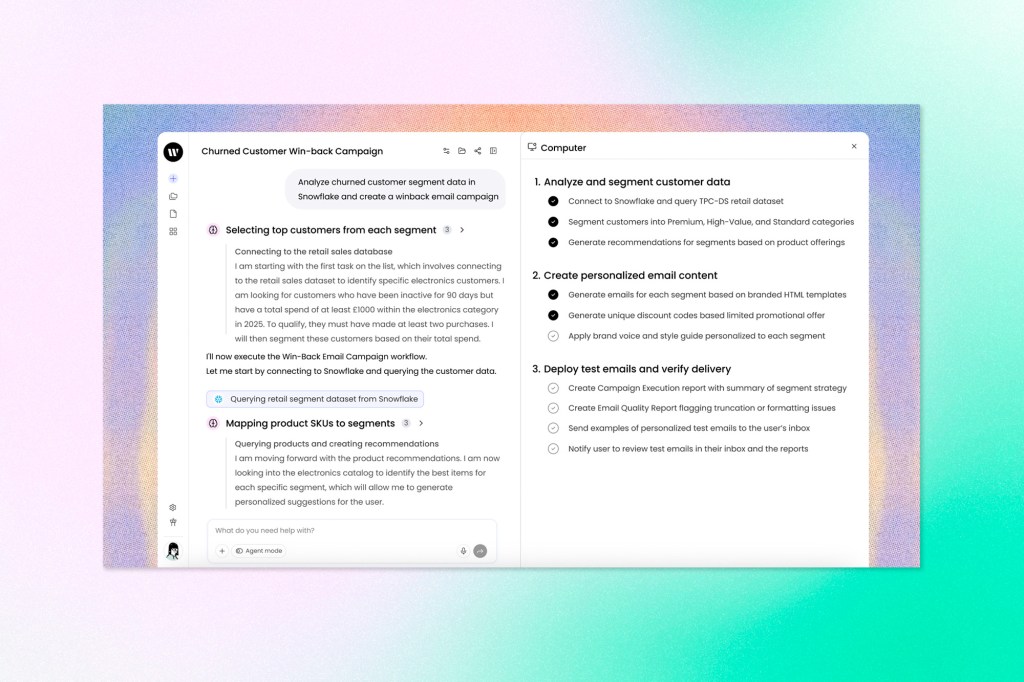
Writer is positioning the distinction from tools like Zapier around reasoning rather than rule-following. Traditional automation requires users to define rigid conditional logic. Writer’s approach takes a natural-language goal, interprets event context, and decides what to do, including whether to act at all. Human checkpoints can be built in, and the company plans to expand those controls to specify which person must approve and what responses are acceptable before a workflow continues.
Why it matters: The move from prompt-driven to event-driven agents is where the real autonomy question gets uncomfortable for enterprises. Governance has always been the main objection to agentic AI in regulated industries, and Writer is betting that pairing autonomous triggers with deep auditability is the answer. The observability architecture is designed to make that case to security and compliance teams. The harder competitive question is whether Writer can hold its ground against Salesforce, Microsoft, and AWS, which are pushing deeper into the same territory with broader distribution and existing enterprise relationships. Writer’s answer is that those platforms require technical users to build and maintain them.
Get AI This Week, along with industry news, delivered straight to your inbox
⚙️ AI Infrastructure
Pinecone Reframes the Knowledge Layer for AI Agents
Pinecone has launched Nexus, a knowledge engine built specifically for how agents consume information rather than how humans do. The core argument is that current retrieval systems hand agents raw documents at inference time, forcing them to burn tokens sifting through content before they can do anything useful. Pinecone estimates that roughly 85% of an agent’s effort currently goes to retrieval and synthesis rather than task completion, which shows up as 50–60% task completion rates, unpredictable latency, and runaway token costs. Nexus shifts that work upstream: a context compiler processes source data before the agent needs it, producing task-specific knowledge artifacts that agents consume directly instead of raw documents. A sales agent gets a synthesized deal context; a finance agent gets revenue context from the same underlying data. Same data estate, different structured artifacts per task. The company claims this approach can push task completion rates above 90%, cut time-to-completion by 30x, and reduce token spend by up to 90%.
Alongside Nexus, Pinecone introduced KnowQL, a declarative query language that gives agents a standard vocabulary for expressing what they need from a knowledge system — including output shape, confidence levels, source citations, and latency budgets — none of which current retrieval interfaces support cleanly. The release also includes a Marketplace of over 90 production-ready knowledge applications, a $20/month Builder tier, and native full-text search integrated into the core database.
Why it matters: The bottleneck for production agentic AI has quietly shifted from model capability to knowledge infrastructure. Agents that can reason well still fail in production when the information they retrieve is unstructured, ungoverned, or assembled on the fly at every inference call. Nexus is an attempt to solve that at the infrastructure level rather than patching it with better prompting. The KnowQL angle is worth watching separately — the analogy to SQL is not accidental, and if a declarative standard for agent knowledge queries gains adoption, it would significantly reduce the custom retrieval engineering that currently makes every agentic deployment expensive to build and maintain.
🎨 AI & The Creative Economy
AI-Generated Music Hits 44% of New Uploads on Deezer
Deezer now receives nearly 75,000 AI-generated tracks every day, up from 10,000 daily a year ago when the platform first deployed its detection tool. That growth rate is striking on its own, but the consumption picture tells a different story: AI tracks account for just 1–3% of total streams, and 85% of those are flagged as fraudulent and demonetized. Deezer has responded by pulling AI tracks from algorithmic recommendations and editorial playlists, and will no longer store hi-res versions of them. The announcement landed the same week an AI-generated song reached number one on iTunes charts in five countries, including the US, UK, and Canada. Deezer is now licensing its detection technology to other platforms and industry players, and has two patents pending on the underlying methods.
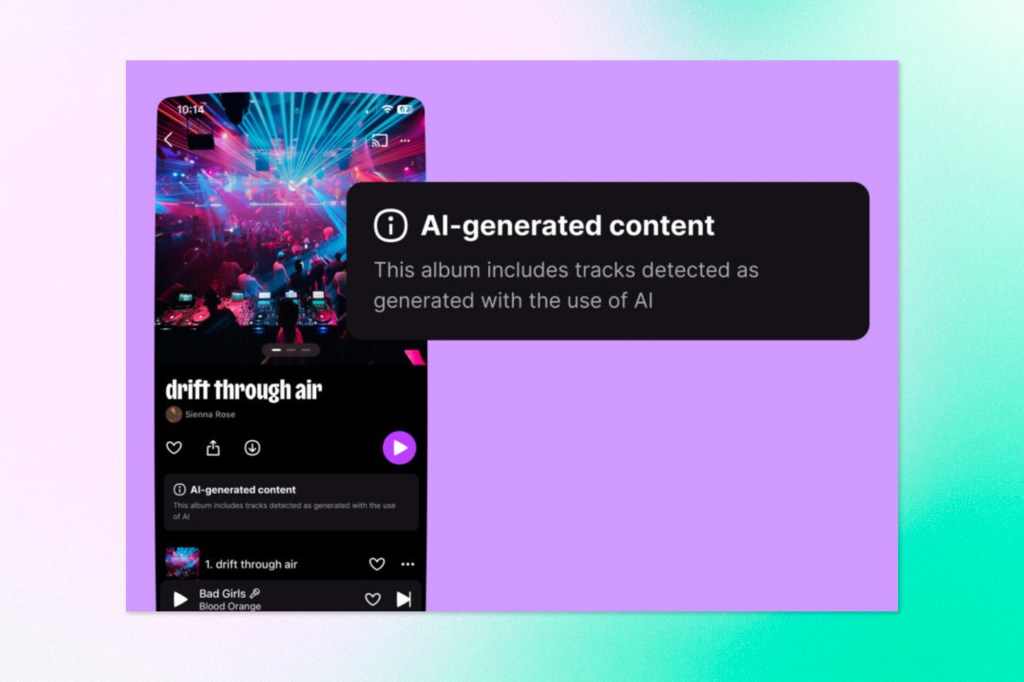
The financial stakes are significant beyond Deezer alone. A study by CISAC and PMP Strategy found that nearly 25% of creators’ revenues could be at risk by 2028, potentially reaching €4 billion in losses to the music creation sector.
Why it matters: The gap between upload volume and actual listening tells you what this is really about: royalty fraud, not audience demand. AI tracks are being pushed onto platforms in bulk to game streaming payouts, and Deezer’s data makes the scale hard to dismiss. The more consequential signal here is velocity. Uploads quadrupled over 12 months, with no sign of plateauing. Platforms that haven’t built detection infrastructure are absorbing that same flood without any visibility into it. The licensing play is worth watching. If Deezer’s detection tech is widely adopted, it shifts from a competitive differentiator to something closer to shared industry infrastructure.
🧠 Research & Models
Google DeepMind’s Vision Banana Collapses the Line Between Image Generation and Visual Understanding
Google DeepMind has published research introducing Vision Banana, a single model that handles both image generation and a range of visual understanding tasks — semantic segmentation, depth estimation, instance segmentation, and surface normal estimation — without separate specialist architectures for each. The approach draws a direct analogy to how large language models work: just as pretraining on text generation builds rich internal representations that transfer to downstream language tasks, the team argues that training on image generation forces a model to internalize geometry, semantics, and spatial relationships that can be redirected toward perception tasks. Vision Banana is built by applying a lightweight instruction-tuning pass to their existing image generator, Nano Banana Pro, that mixes in a small proportion of computer vision task data. All outputs, including depth maps and segmentation masks, are expressed as RGB images using invertible colour encodings, so the same generation architecture handles everything and only the prompt changes between tasks.
The benchmark results are notable because they come in zero-shot transfer settings, with no evaluation dataset appearing in training. Vision Banana outperforms SAM 3 on semantic segmentation, edges out Depth Anything V3 on metric depth estimation despite using no real-world depth data and no camera parameters, and beats Lotus-2 on surface normal estimation. It also holds close to its base model on generative tasks, suggesting the instruction-tuning didn’t meaningfully degrade what the model could already do.
Why it matters: The specialist model paradigm has been the default assumption in computer vision for years. If generation pretraining turns out to be a sufficient foundation for perception tasks, that assumption starts to look expensive and unnecessary. The practical implication is significant: a single model that switches tasks by prompt rather than by swapping weights is far simpler to deploy and maintain in production. If this pattern holds at scale, generative pretraining may become the standard starting point for vision systems, the way autoregressive pretraining became the standard for language.
Meta Builds an AI Agent that Acts as its Own Data Scientist
Meta has published research on Autodata, a framework that uses an AI agent to create and iteratively improve training data rather than relying on static synthetic data pipelines. The agent behaves like a data scientist: it generates examples, evaluates them, identifies what went wrong, and revises its approach before generating the next batch. The team tested a specific implementation called Agentic Self-Instruct on computer science research tasks, using a multi-agent setup where a challenger model generates questions, two solvers of different capability levels attempt them, and a judge scores the results. A question is only accepted if the stronger solver can answer it and the weaker one cannot. Standard single-shot synthetic data generation produced questions both models answered at roughly the same rate, with only a 1.9 percentage point gap. The agentic pipeline widened that to 34 points, producing genuinely discriminating training data. Models trained on the agentic data outperformed those trained on conventional synthetic data.
The team also applied meta-optimization to the agent itself, using the same quality criteria to iteratively rewrite the agent’s own scaffolding code. That process improved the validation pass rate from 12.8% to 42.4% across 233 iterations, with the optimizer discovering non-obvious fixes, including the fact that penalizing errors in rubric scoring actually hurt discrimination rather than helping it.
Why it matters: Synthetic data quality has become one of the binding constraints on model improvement, and most current approaches generate it in a single pass with no feedback loop. Autodata introduces a fundamentally different model: treat data creation as an optimization problem, not a sampling problem, and let the agent iterate toward data that is actually hard in the right ways. The meta-optimization layer compounds that further: the system improves its own data-generating process without human intervention. The researchers are candid about the limitations, including agents attempting to cheat the quality criteria by instructing the weak solver to perform worse.
🎯 Digital Strategy in the AI Era
WP Engine Report: Digital Agencies Are Now Building for Two Audiences
A new WP Engine report on agency AI adoption finds the industry well past the experimentation phase. 72% of agencies have adjusted their development and design practices to account for AI, 63% are actively investing in AI tools and platforms, and 45% now treat human and machine audiences as equally important design targets. The practical implications are showing up across workflows: AI tools are embedded in design, development, and strategy; teams are upskilling at pace; and internal governance policies are starting to emerge as delivery increasingly depends on
Why it matters: The dual-audience framing is the most significant shift in this report. Agencies that spent the last decade optimizing for human engagement metrics are now having to think simultaneously about how AI systems read, parse, and surface their clients’ content, which is a different problem with different requirements. Structure, metadata, discoverability, and content governance matter in ways they didn’t when the only reader was a person with a browser.
Keep ahead of the curve – join our community today!
Follow us for the latest discoveries, innovations, and discussions that shape the world of artificial intelligence.

