
The pace hasn’t slowed. This week brought a wider look at OpenAI’s hardware ambitions, a notable reasoning benchmark from Google, Anthropic’s first serious look at agent behaviour in the wild, and a research release that quietly challenges how the industry thinks about model transparency.
Listen to the AI-Powered Audio Recap
This AI-generated podcast is based on our editor team’s AI This Week posts. We use advanced tools like Google NotebookLM, Descript, and Elevenlabs to turn written insights into an engaging audio experience. While the process is AI-assisted, our team ensures each episode meets our quality standards. We’d love your feedback—let us know how we can make it even better.
TL;DR
- OpenAI’s first hardware product is shaping up to be a camera-equipped smart speaker, with a wider device roadmap that includes earbuds, glasses, and more.
- Google released Gemini 3.1 Pro, posting a benchmark result on novel logic tasks that’s more than double its predecessor.
- Anthropic launched Claude Code Security to help teams find and patch vulnerabilities that traditional tools miss, and published research on how autonomous agents are actually being used in the real world.
- Telex updated its WordPress block builder with image upload support and a round-trip editing workflow that bridges AI generation and traditional development.
- Google’s Opal workflow tool gained agentic capabilities, including memory, dynamic routing, and mid-workflow chat.
- Guide Labs open-sourced Steerling-8B, a model built with interpretability at its core rather than as an afterthought.
📱 Consumer AI
OpenAI’s Hardware Ambitions Take Shape
The details around OpenAI and Jony Ive’s hardware collaboration keep expanding. What started as whispers about a single mystery device has grown into a surprisingly wide product roadmap — and the first release is coming into focus.
According to a report from The Information, OpenAI’s debut hardware product is expected to be a smart speaker with a camera, likely priced between $200 and $300. The device would be able to identify objects in its surroundings, pick up on nearby conversations, and use facial recognition to enable purchases. A release before March 2027 isn’t expected.
Beyond the speaker, OpenAI is reportedly prototyping smart glasses and a smart lamp, though neither appears close to launch. The glasses, notably, may not reach mass production until 2028. That’s worth flagging, given that Sam Altman had previously said the Ive collaboration wasn’t producing glasses.
The wider device list also reportedly includes a smart earbud (with supply chain leaks pointing to a September release), a smart pin, and a smart pen. Of the bunch, the earbud feels like the most practical near-term bet, and the pin concept draws some uncomfortable comparisons to the Humane AI Pin, which didn’t exactly set the world on fire.
Whatever form these devices take, their real differentiator won’t be the hardware. It’ll be ChatGPT Voice. Compared to Siri and Alexa, it’s in a different league entirely, and that could be what makes OpenAI’s gadgets worth watching when they eventually arrive.
Why it matters: The device roadmap itself is less significant than what it signals about where AI competition is heading. The major platforms have largely converged on model capability as a differentiator, and that gap is narrowing fast. Hardware is the next frontier for lock-in. Whoever owns the physical interface closest to the user controls the relationship with the AI. OpenAI isn’t just trying to sell a speaker; it’s trying to own the room.
⚙️ Model Updates
Google Upgrades Its Core Gemini Intelligence
Google has released Gemini 3.1 Pro, an updated version of its flagship model designed for complex reasoning tasks where a straightforward answer won’t cut it. The release follows last week’s update to Gemini 3 Deep Think, and represents the underlying intelligence powering those advances.
The headline benchmark number is a 77.1% score on ARC-AGI-2, a test designed to evaluate how well a model handles entirely new logic patterns it hasn’t seen before. According to Google, that’s more than double the reasoning performance of its predecessor, 3 Pro.

On the practical side, 3.1 Pro can generate animated SVGs directly from a text prompt, producing code-based animations that scale without quality loss and come in at a fraction of the file size of traditional video formats. Google is positioning this as one example of what “intelligence applied” looks like in everyday creative and technical work.
The rollout is starting in preview today across a wide range of Google products: consumers can access it through the Gemini app (on Pro and Ultra plans) and NotebookLM, while developers and enterprises can get started through the Gemini API, AI Studio, Vertex AI, Antigravity, Gemini CLI, and Android Studio. A general availability release is expected soon.
Why it matters: The ARC-AGI-2 benchmark result is worth paying attention to, not because benchmark scores tell the whole story, but because this particular test is specifically designed to resist memorization. Doubling performance on novel logic problems is a different kind of progress than improving on tasks where training data overlap is a factor. It suggests reasoning gains that may actually transfer to problems the model hasn’t seen before.
🎨 Google’s Image Generator Gets a Speed Upgrade
Also out this week from Google: Nano Banana 2, the latest version of its image generation model, now available across the Gemini app, Search, AI Studio, Vertex AI, and Flow. The short version is that it brings the quality and reasoning capabilities previously reserved for Nano Banana Pro to a faster, more broadly accessible tier.
The practical improvements are meaningful for production use. The model can maintain consistent appearance across up to five characters and fourteen objects within a single workflow, which matters for anyone using it to build visual narratives or storyboards. Text rendering has also improved, with support for legible in-image text generation and translation across languages. Resolution support runs from 512px up to 4K, covering most professional output needs.
On the provenance side, Google is coupling its SynthID watermarking technology with C2PA Content Credentials, giving viewers a more complete picture of how an image was made, not just whether AI was involved. SynthID verification in the Gemini app has already been used over 20 million times since its November launch.
Why it matters: The image generation market is competitive and moving fast, but the provenance work is the piece worth watching longer term. As AI-generated imagery becomes harder to distinguish from photography, the infrastructure for verifying origin becomes a trust layer for the entire ecosystem. Google embedding that verification directly into its products, at scale, sets a precedent the rest of the industry will likely have to follow.
🛡️ Enterprise & Security
Anthropic Takes Aim at Cybersecurity and Agent Oversight
Anthropic had a busy week on two fronts: securing codebases and studying how people actually use AI agents in the wild.
On the security side, the company launched Claude Code Security in a limited research preview, opening it up to Enterprise and Team customers as well as open-source maintainers. The tool goes beyond traditional static analysis, which typically flags known vulnerability patterns like exposed credentials or outdated encryption. Instead, it reasons through code the way a human security researcher would, tracing how data moves through an application and surfacing the kind of context-dependent flaws that rule-based tools tend to miss. Each finding goes through a multi-stage verification process before it reaches a developer, with confidence ratings and severity scores attached, and nothing gets patched without human sign-off. The research behind it is notable: using Claude Opus 4.6, Anthropic’s team found over 500 vulnerabilities in production open-source codebases, some of which had gone undetected for decades.
Separately, Anthropic published a research report analyzing millions of real-world interactions with Claude Code and its public API to better understand how autonomous agents are actually being used. A few findings stood out. The longest Claude Code sessions have nearly doubled in length over three months, with top-percentile runs now exceeding 45 minutes. As users gain experience, they tend to grant the tool more autonomy, though they also interrupt more frequently when something needs correcting. Perhaps most interesting: Claude Code asks for clarification more than twice as often as users interrupt it on complex tasks, suggesting the model is doing some of its own oversight work rather than waiting to be stopped.
Software engineering still accounts for nearly half of all agentic activity, but usage is beginning to appear in healthcare, finance, and cybersecurity. The vast majority of actions are low-risk and reversible, but Anthropic is clear-eyed that this landscape will shift as agents become more capable and more widely adopted.
Why it matters: The agent autonomy research is one of the first serious attempts by a major lab to study how its own technology is actually being used in deployment, rather than relying solely on controlled evaluations. The gap between what models are capable of and what users currently allow them to do is closing quickly. Understanding that dynamic now, before autonomous agents become routine in high-stakes domains, is exactly the kind of work that tends to get skipped when the industry moves fast.
Get AI This Week along with industry news, delivered straight to your inbox
⚒️ Tools & Platforms
Telex Gets Smarter for WordPress Block Builders
Telex, Automattic’s AI-powered WordPress block creation tool, has rolled out a meaningful set of updates since its August launch. The biggest addition is image upload support: you can now drop in a Figma mockup, a screenshot, or even a hand-drawn sketch alongside your prompt, and Telex will use that as a visual reference when generating your block. For complex layouts or specific design aesthetics, this is a significant improvement over trying to describe every detail in text.
Developers also get a proper round-trip workflow now. You can download a generated block, edit it in VS Code, Cursor, or any other editor you prefer, then upload it back to Telex to continue refining with AI. It bridges the gap between AI generation and hands-on development in a way that should feel natural to anyone already working in code.
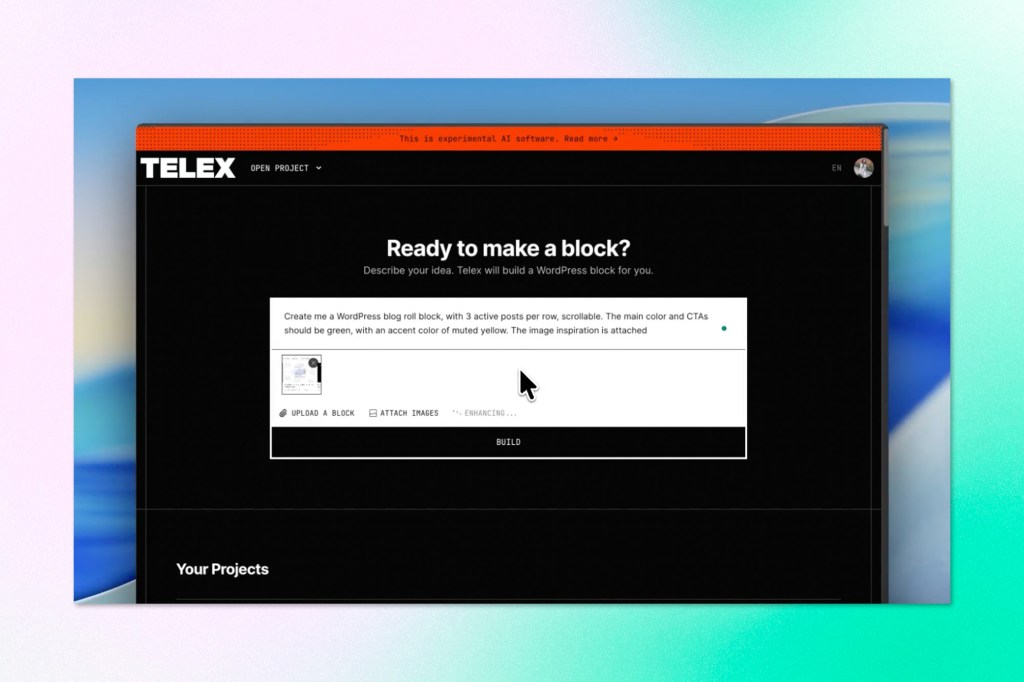
Version history has also been improved: restoring a previous version now creates a new version rather than overwriting your current work, making it safer to explore past iterations or recover something you deleted a few prompts back. Rounding out the update are localization support across seven languages, fixes for multi-byte character streaming issues, dynamic page titles, save confirmations for manual edits, and cleaner share links.
For WordPress developers experimenting with AI-assisted block creation, this is a tool worth revisiting.
Why it matters: The round-trip editing workflow is the detail worth watching here. Most AI-assisted development tools still operate as isolated generators; you get an output, and then you’re on your own. Bringing the edited code back into the AI loop treats generation and refinement as a continuous process rather than a one-shot transaction. That’s a more honest model of how developers actually work, and it points toward where AI coding tools need to go broadly.
Google’s Opal Gains Agentic Workflows
Google Labs has updated Opal, its workflow builder, with a new agent step that replaces the previous model-selection approach with something more goal-oriented. Rather than manually configuring which model handles each part of a workflow, users now describe what they want to accomplish and the agent determines the path, pulling in tools like web search or video generation as needed.
The update also introduces three new capabilities that significantly expand what Opal workflows can do. Memory allows an Opal to retain information across sessions, so preferences and context carry over without users repeating themselves. Dynamic routing lets workflows branch based on custom conditions, directing the agent down different paths depending on the situation, and interactive chat gives the agent a way to ask follow-up questions mid-workflow when it needs more information before proceeding.
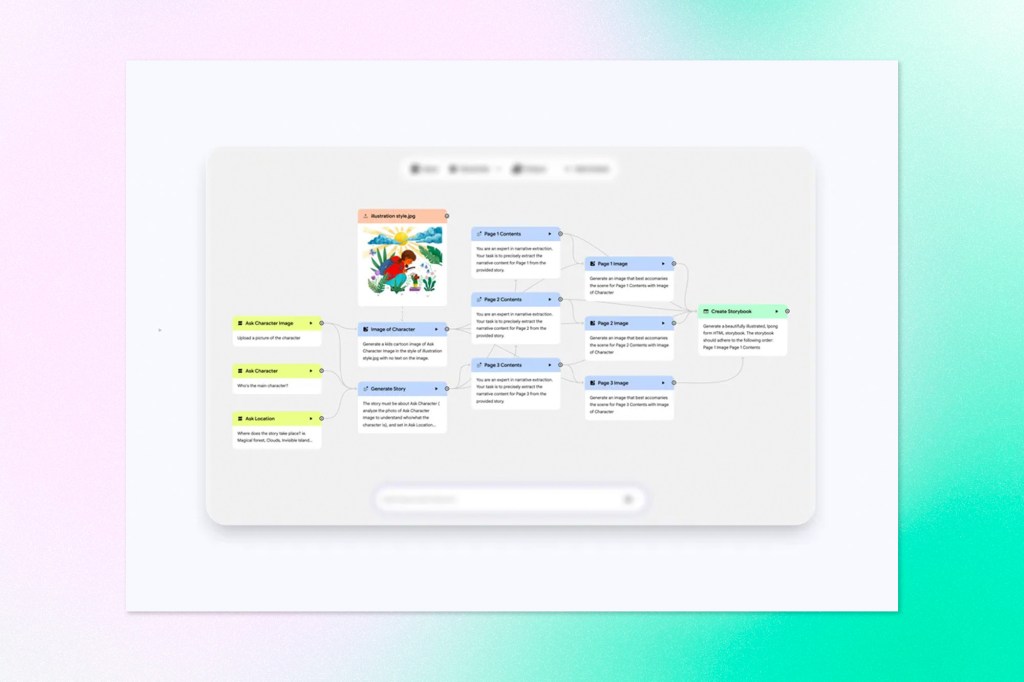
The practical effect is a shift from workflows that produce a fixed output to ones that feel more like an ongoing collaboration. The interior design example Google highlights illustrates this well: instead of uploading a photo and receiving a single generated image, the agent iterates with the user, refines its understanding of their aesthetic, and adjusts accordingly.
Why it matters: Opal is an early indicator of how general-purpose workflow tools are evolving. The addition of memory and dynamic routing, in particular, moves it closer to a genuine automation layer rather than a prompt wrapper. For businesses exploring AI-assisted processes without deep technical resources, tools like this lower the barrier significantly. The more interesting question is whether users will trust an agent to make routing decisions autonomously, or whether they will continue to reach for the manual controls.
🖥️ Perplexity Launches a Multi-Model Autonomous Worker
Perplexity has introduced Perplexity Computer, a system designed to go beyond answering questions or completing discrete tasks. The pitch is a general-purpose digital worker that can plan, delegate, and execute entire workflows autonomously, potentially running for hours or longer without requiring hands-on management.
The way it works is straightforward in concept: you describe an outcome, and the system breaks it into tasks and subtasks, spinning up sub-agents to handle each one in parallel. Those agents can conduct research, generate documents, process data, write code, and call connected services, all within isolated compute environments with access to a real browser and filesystem. If a sub-agent hits a wall, it creates additional agents to work around the problem, only surfacing to the user when genuinely stuck.
The model strategy is notable. Rather than betting on a single model, Perplexity is orchestrating across the current frontier: Claude Opus 4.6 handles core reasoning, Gemini manages deep research, Grok handles lightweight tasks requiring speed, and ChatGPT is used for long-context recall. The framing is that models are specializing rather than commoditizing, and that the most powerful system is the one that can deploy each where it performs best.
Perplexity Computer is available now to Max subscribers, with enterprise access coming soon.
Why it matters: Most AI products are still built around a single model relationship. Perplexity is making a direct argument that multi-model orchestration is the more durable architecture, and backing it with a product rather than a white paper. If that approach scales, it puts pressure on single-model platforms to either match the flexibility or justify why their model alone is enough.
🔍 Research
A Startup Is Building LLMs You Can Actually See Inside
Most AI models are engineered for performance first, with interpretability treated as something to figure out later. Guide Labs is flipping that logic. The San Francisco startup released Steerling-8B this week, an 8-billion-parameter model built from the ground up to be interpretable. The core idea is an embedded concept layer that organizes training data into traceable categories during the model’s construction. What this means in practice is that you can follow the thread from any output back to where it came from, whether you’re checking a factual claim or interrogating something more structural, like how the model encodes bias. Existing interpretability techniques try to answer those questions by analyzing a finished model from the outside. Guide Labs argues that the approach is inherently fragile and that the more reliable path is to engineer the answers in from the start.
The real-world motivation is easy to see. Financial institutions that deploy models that influence credit decisions face legal and ethical obligations regarding which factors those models may consider. Scientific teams using AI for research, like protein structure prediction, need to understand the reasoning, not just the result. And for consumer-facing products, better internal visibility means more reliable control over what gets surfaced and what doesn’t.
Why it matters: Interpretability has mostly been treated as a research problem, something to investigate after a model is already deployed. Guide Labs is making the case that it’s an engineering problem with a practical solution. If that holds up at scale, it changes the calculus for regulated industries that have been cautious about AI adoption, not because the technology doesn’t work, but because they can’t audit it. The question of whether interpretable-by-design models can match frontier performance is still open, but it’s now a question worth asking seriously.
Keep ahead of the curve – join our community today!
Follow us for the latest discoveries, innovations, and discussions that shape the world of artificial intelligence.

