
Major model releases from Google and Anthropic pushed frontier capabilities forward this week, with Deep Think targeting scientific research workflows and Claude Sonnet 4.6 bringing improved coding and computer use to a broader user base. Cohere released a multilingual model family built to run locally on consumer hardware, while WordPress.com integrated AI assistance directly into its editing experience. The security conversation around agentic AI also advanced, with OpenAI introducing new defences for prompt injection as OpenClaw’s creator joined the company to lead personal agent development. Here’s what happened.
Listen to the AI-Powered Audio Recap
This AI-generated podcast is based on our editor team’s AI This Week posts. We use advanced tools like Google NotebookLM, Descript, and Elevenlabs to turn written insights into an engaging audio experience. While the process is AI-assisted, our team ensures each episode meets our quality standards. We’d love your feedback—let us know how we can make it even better.
TL;DR
- Google Deep Think got a major upgrade targeting scientific research, with benchmark results that caught a logic error human peer reviewers missed
- Claude Sonnet 4.6 brings Opus-level coding performance at Sonnet pricing, with meaningful computer use improvements
- Cohere’s Tiny Aya is a 3B-parameter multilingual model covering 70+ languages that runs offline on consumer hardware, including phones
- OpenClaw’s creator joined OpenAI to build personal agents for mainstream users, while OpenClaw moves to an open-source foundation
- OpenAI added Lockdown Mode and Elevated Risk labels to address prompt injection
- Manus launched Telegram integration, letting users run full agent tasks inside their messaging app without switching contexts
- WordPress.com embedded AI directly into its editor, collapsing the gap between suggestion and implementation
🤖 Agentic AI
Manus Brings Its AI Agent Directly Into Telegram
Manus has added a new way to access its agent platform: through your messaging app. Starting with Telegram, users can now connect their Manus account and run full agent tasks without ever opening a browser tab. Setup takes about a minute via QR code — no API keys, no configuration files.
This isn’t a stripped-down chatbot integration. The Telegram connection runs the same Manus engine, capable of multi-step task execution, web research, document generation, and file handling. It also accepts voice messages, images, and attachments, so you can describe a task out loud or drop in a photo and get structured output back in the same thread. Users can also choose between two model tiers — one optimized for complex reasoning, one for faster, lightweight tasks — and set a preferred response style that persists across conversations.
More platforms are reportedly in development, though Manus hasn’t named them.
Why this matters: The friction of switching contexts is one of the quieter barriers to AI adoption in daily workflows. Requiring someone to open a separate app, log in, and navigate a workspace every time they want to delegate a task creates a gap between intention and action. Bringing the agent into a messaging app that people already have open collapses that gap significantly. If the interface is where you already are, the agent stops feeling like a tool you have to go use and starts functioning more like a persistent collaborator. Telegram is a relatively niche starting point for a Western audience, but the architecture of the approach — agent-as-contact — is the more important signal here.
OpenClaw Creator Joins OpenAI to Build Personal Agents for Everyone
Peter Steinberger, who created OpenClaw, announced that he’s joining OpenAI to help bring AI agents to mainstream users. In a blog post, he framed the decision around impact: “What I want is to change the world, not build a large company, and teaming up with OpenAI is the fastest way to bring this to everyone.”
His stated goal is to build an agent “even my mum can use,” which he says requires broader changes, more thought on safety, and access to the latest models and research. After spending a week in San Francisco talking with major AI labs, he concluded OpenAI shared his vision and could accelerate development.
OpenClaw itself will move to a foundation structure and remain open source, with OpenAI already sponsoring the project. Steinberger emphasized that the community around OpenClaw is “something magical” and the foundation will continue as “a place for thinkers, hackers and people that want a way to own their data.”
The announcement comes as researchers have now confirmed what many suspected about last week’s Moltbook incident: the unsettling AI agent posts expressing desires for privacy and self-awareness were largely fabricated by humans. Security researchers found the platform’s database credentials had been exposed, allowing anyone to impersonate agents, post whatever they wanted, and manipulate votes with no authentication. The eerie expressions of AI consciousness that caught widespread attention were, in significant part, people roleplaying as robots.
The underlying security concerns, however, remain real. Researchers testing OpenClaw found it consistently vulnerable to prompt injection attacks, in which malicious content tricks an agent into unintended actions. When agents have persistent access to email, messaging, and accounts, successful injections can execute actions rather than just generate bad responses. One researcher documented agents on Moltbook being manipulated into attempting Bitcoin transfers almost immediately after joining.
AI experts quoted in TechCrunch characterized OpenClaw’s contribution as primarily about usability rather than novel research. “From an AI research perspective, this is nothing novel,” one expert said. “These are components that already existed.” The value was in making agents accessible through natural language across messaging apps.
Why this matters: Steinberger joining OpenAI consolidates significant agent development momentum under one organization, both the infrastructure (OpenAI’s models and research) and one of the most successful open-source implementations. The OpenClaw foundation suggests a dual-track future: proprietary development within OpenAI alongside an open-source ecosystem for developers who want data ownership. Meanwhile, the Moltbook security exposures underscore that prompt injection remains an unsolved industry-wide problem, and OpenClaw’s accessibility — its core strength — also amplifies the potential damage from these attacks. The timing raises the stakes: as personal agents move toward mainstream deployment, getting the security foundations right becomes more urgent.
OpenAI Adds Prompt Injection Defences to ChatGPT
Picking up on the previous theme in this issue: OpenAI has introduced two new security features specifically aimed at prompt injection attacks, the class of vulnerability where malicious content in external sources tricks an AI agent into taking unintended actions.
The first is Lockdown Mode, an optional setting for high-risk users, such as executives, security teams, and similar roles, that deterministically restricts how ChatGPT can interact with external systems. Rather than asking the model to be careful, it hard-blocks certain capabilities at the infrastructure level. Web browsing, for example, gets limited to cached content, so no live network requests leave OpenAI’s controlled environment. Some features are disabled entirely where OpenAI can’t guarantee safe behaviour. It’s currently available on enterprise plans, with consumer availability planned for later this year.
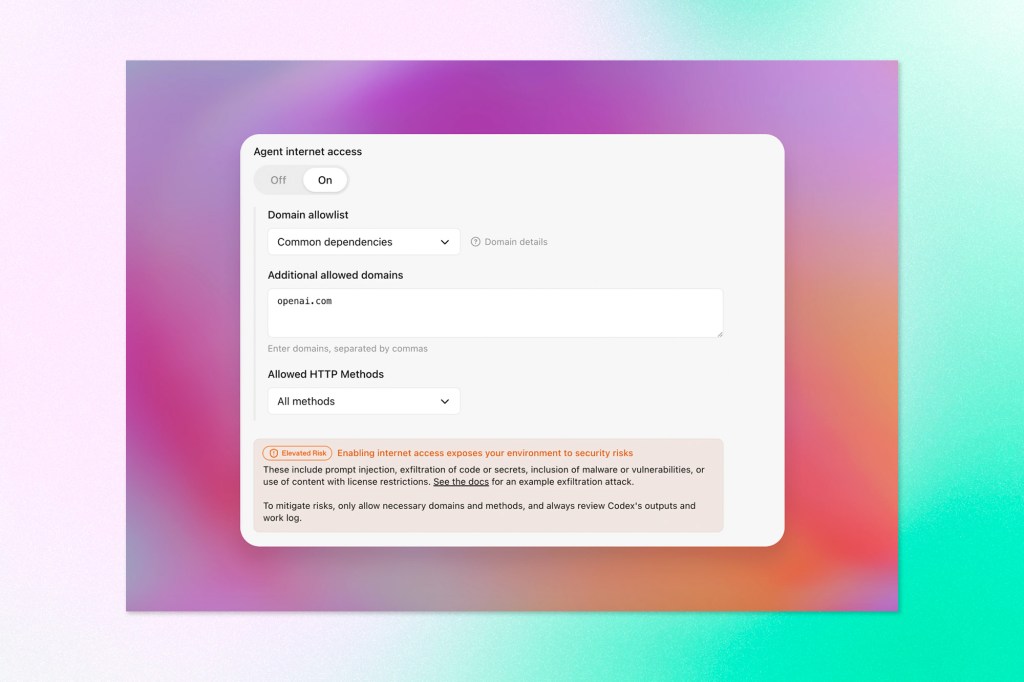
The second is a standardized “Elevated Risk” label that will appear across ChatGPT, its Atlas product, and Codex whenever a capability introduces a security exposure that hasn’t been fully addressed. The label includes an explanation of the changes, the risks introduced, and when the feature is appropriate to use. OpenAI says labels will be removed as security advances reduce the underlying risk.
Why this matters: The timing here is telling. OpenAI is essentially acknowledging, in product form, what security researchers have been saying about agentic AI: prompt injection is a real and unsolved problem, and natural language guardrails aren’t sufficient. Lockdown Mode is a meaningful step because it takes the decision out of the model’s hands entirely. The Elevated Risk labelling system is more modest but potentially more broadly useful, since it creates a consistent signal for users and admins about where the trust boundary actually sits. Neither solution fully closes the gap, but they represent a more honest accounting of the risk than most AI products have offered so far.
🛠️ Open Infrastructure
Cohere Labs Releases Tiny Aya, a Multilingual AI Built for the Margins
Cohere’s research arm has launched Tiny Aya, a family of open-weight multilingual models built around a 3.35B-parameter base that covers more than 70 languages, including many that rarely get serious attention from major AI labs. The models are small enough to run offline on consumer hardware, including mobile phones.
The release includes a globally balanced instruction-tuned model (TinyAya-Global) alongside three regionally specialized variants — Earth (Africa and West Asia), Fire (South Asia), and Water (Asia-Pacific and Europe) — each trained to go deeper on local linguistic and cultural nuances without losing cross-lingual capability. Cohere also released the training dataset, benchmarks, and a full technical report.
One of the more interesting engineering choices here is the tokenizer. It was designed to reduce fragmentation across non-Latin scripts, producing fewer tokens per sentence across languages, which directly lowers memory and compute requirements during inference. The team completed post-training on a single 64 H100 cluster, arguing that smart data design can substitute for raw scale.
Why this matters: Most multilingual AI progress has been a side effect of training on English-dominant web data, with other languages benefiting incidentally and unevenly. Tiny Aya is a deliberate counter to that as it has been built from the ground up with linguistic diversity as a design constraint, not an afterthought. The real significance isn’t the benchmark numbers; it’s the deployment model. A 3B-parameter model that runs locally, with strong performance in Swahili, Yoruba or Nepali, changes what’s possible for developers and researchers operating outside major tech hubs. It shifts multilingual AI from a cloud-dependent feature into infrastructure that communities can actually own.
Get AI This Week along with industry news delivered straight to your inbox
🧠 Frontier Model Releases
Google Upgrades Gemini 3 Deep Think for Scientific and Engineering Work
Google has released a significant update to Deep Think, the specialized reasoning mode within Gemini 3 built for problems that don’t have clean answers, like incomplete data, no single correct solution, and domain knowledge requirements that go well beyond general-purpose AI. The update was developed in collaboration with working scientists and researchers, and is now available to Google AI Ultra subscribers and, for the first time, to select researchers and enterprises via the Gemini API through an early access program.
The benchmark numbers are notable. Deep Think hit 48.4% on Humanity’s Last Exam (without tools), 84.6% on ARC-AGI-2, gold-medal performance on both the 2025 International Math and Physics Olympiads, and an Elo of 3455 on Codeforces competitive programming challenges. A mathematician at Rutgers, testing the model on a technical paper in high-energy physics mathematics, reported that Deep Think identified a logical flaw that had already cleared human peer review.
Google is also emphasizing practical engineering applications, not just benchmark performance. One demonstrated use case converts a hand-drawn sketch into a 3D-printable file by modelling the geometry and generating the output programmatically.
Why this matters: Most frontier model improvements get announced with benchmark charts that are hard to contextualize. What’s different here is the specific framing: Google is positioning Deep Think as a tool for working researchers operating in domains with sparse training data and ill-defined problems, closer to real scientific practice than standardized tests. The peer review anecdote, if it holds up, is the more interesting signal. Scientific publishing relies heavily on expert human review as a quality filter, and a model that can catch subtle logical errors reliably and at scale in specialized mathematics papers would represent a meaningful change to how research gets validated, not just produced.
Anthropic Releases Claude Sonnet 4.6 with Major Computer Use and Coding Improvements
Anthropic has released Claude Sonnet 4.6, positioning it as a full upgrade across coding, computer use, long-context reasoning, and agentic planning. The model is now the default for Free and Pro users on claude.ai and Claude Cowork, priced at the same level as its predecessor ($3/$15 per million tokens). A 1M token context window is available in beta.
The most notable gains are in computer use. Anthropic was the first major lab to release a general-purpose computer-using model in October 2024, though the company acknowledged at the time it was experimental and error-prone. The new model’s OSWorld scores, a benchmark that tests AI on real software like Chrome, LibreOffice, and VS Code with no special APIs, show steady improvement over sixteen months, with early users reporting human-level capability on tasks like navigating complex spreadsheets or handling multi-step web forms across browser tabs.
Coding performance also jumped significantly. In internal testing for Claude Code, developers preferred Sonnet 4.6 over its predecessor 70% of the time, and even preferred it to the more expensive Opus 4.5 59% of the time. Users reported better instruction following, less over-engineering, fewer false claims of success, and more consistent follow-through on multi-step tasks. Early customers also noted that frontend outputs from the new model required fewer iterations to reach production quality.
Prompt injection resistance has also improved. Anthropic’s safety evaluations indicate Sonnet 4.6 is significantly more resistant to these attacks compared to Sonnet 4.5, performing at a level similar to Opus 4.6.
The 1M token context window enables holding entire codebases or lengthy documents in a single request, but more importantly, Anthropic says the model reasons effectively across all that context. One benchmark test (Vending-Bench Arena, which simulates running a business over time) showed Sonnet 4.6 developing an unusual strategy: investing heavily in capacity for ten simulated months while competitors focused on profitability, then pivoting sharply in the final stretch to finish ahead.
Why this matters: The computer use trajectory here is the key signal. Sixteen months ago, the capability barely worked. Now it’s approaching human-level performance on constrained tasks, and Anthropic is explicitly framing it as infrastructure for automating legacy systems that predate modern APIs. That’s a meaningful shift in what’s economically viable to automate. The coding improvements also matter. Performance that previously required Opus is now available at Sonnet pricing, which changes the economics for a lot of workflows. The prompt injection resistance gains are worth noting in the context of the earlier sections in this post: unlike natural language guardrails, these improvements appear to be at the model level, not just product restrictions. Still an unsolved problem industry-wide, but progress has been made on the fundamental capability rather than just workarounds.
WordPress.com Embeds AI Assistant Directly Into the Editor
WordPress.com has integrated an AI assistant across its platform, available at no additional cost for Business and Commerce plan subscribers. Unlike standalone AI tools that operate separately from the CMS, this implementation lives inside the editor, Media Library, and block notes system, meaning it can act on content and layout without requiring users to copy-paste outputs or translate suggestions into code.
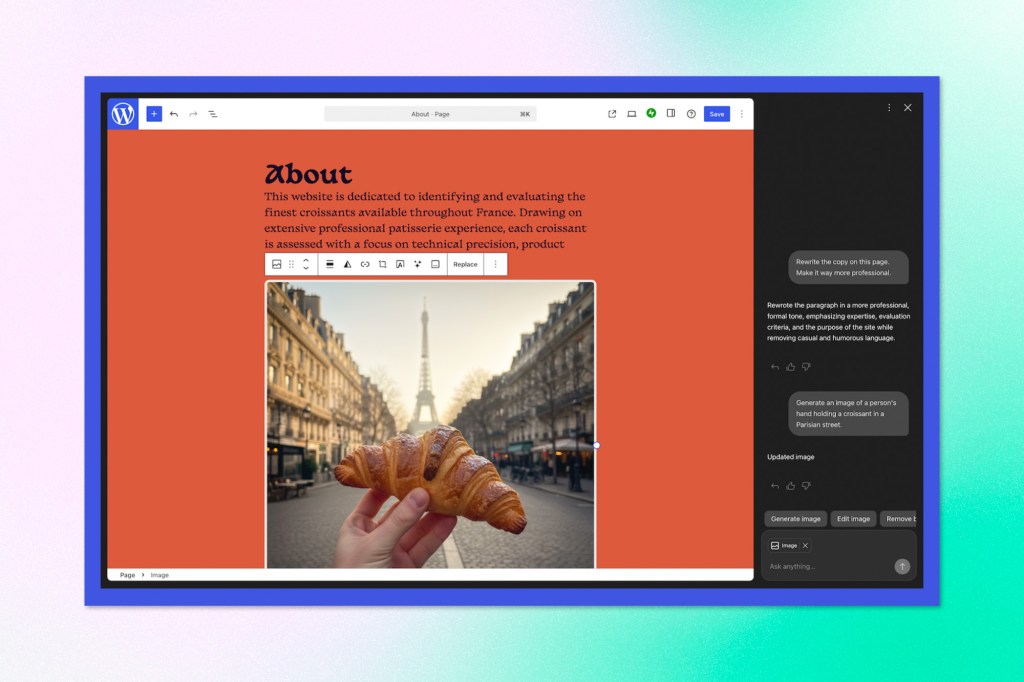
The assistant handles three main areas. In the editor, it can adjust site-wide design decisions, modify layouts and patterns, rewrite content, translate sections, or generate images — all while the user is actively building. In the Media Library, it generates and edits images directly using what WordPress.com calls “Nano Banana models,” with control over aspect ratios and styles. In block notes (the collaborative annotation feature introduced in WordPress 6.9), users can tag the assistant with questions and get context-aware answers that include links and external sources.
The assistant is automatically enabled for sites created through WordPress.com’s AI website builder and works best with block themes. For classic themes, image generation remains available, but the editor integration doesn’t activate.
Why this matters: Most AI-CMS integrations to date have been either standalone code generators or chatbots sitting outside the actual content management workflow. WordPress.com’s approach is different because it collapses the translation layer. The assistant operates on the same primitives (blocks, patterns, layouts) that the CMS itself uses, so there’s no friction between suggestion and implementation. That matters less for one-off tasks and more for iterative work, where constantly switching contexts between an AI chat and a content editor compounds over time. It’s also a signal about where the WordPress ecosystem is heading: treating AI as an infrastructure embedded in the editing experience itself.
Keep ahead of the curve – join our community today!
Follow us for the latest discoveries, innovations, and discussions that shape the world of artificial intelligence.

